Kubernetes는 컨테이너 오케스트레이션 영역에서 거의 표준으로 자리 잡은 오픈소스 시스템입니다. kubernetes를 사용하게 되면 여러대의 노드를 하나의 클러스터로 묶어서 사용가능하게 됩니다. 클러스터를 구성하는 노드들중에 일부에 장애가 발생하더라도 장애가 난 곳에 있던 컨테이너가 kubernetes에 의해 다른 정상상태의 노드로 옮겨가게 되어서 컨테이너로 제공하던 서비스에 지장이 없이 서비스가 지속될 수 있게 해줍니다. 그래서 실제로 서비스를 운영할 때는 컨테이너만을 단독으로 사용하기 보다는 이런 오케스트레이터와 함께 사용하는 경우가 많습니다.
kubernetes를 사용하면 배포를 보다 편리하게 할 수 있다는 장점도 있습니다. 앱을 실행할 컨테이너만 준비해서 kubernetes에 제출하면 kubernetes가 알아서 배포절차를 진행합니다. 카카오에서 컨테이너 플랫폼을 운영하면서 가장 많이 받는 질문중 하나가 “배포중에 트래픽 유실은 없나요?” 입니다. 트래픽이 큰 서비스를 운영하면서 서비스의 품질을 유지하려면 배포중에도 트래픽 유실이 없어야 합니다. 이 글에서는 kubernetes를 사용해서 배포했을때 트래픽 유실이 없게하기 위해서 어떤 점들을 유의해야 하는지 알아보도록 하겠습니다.
kubernetes pod, service, ingress 관계
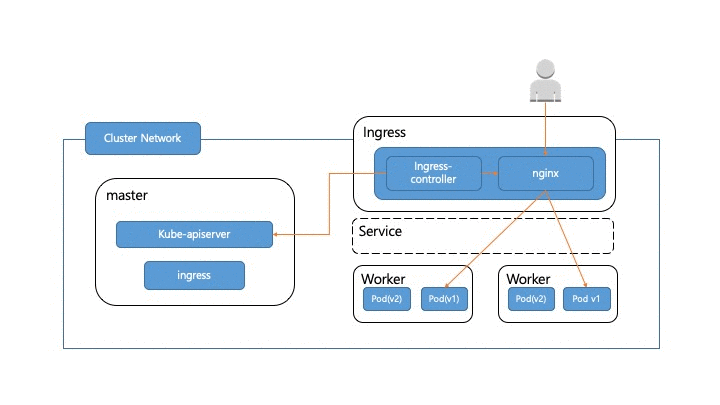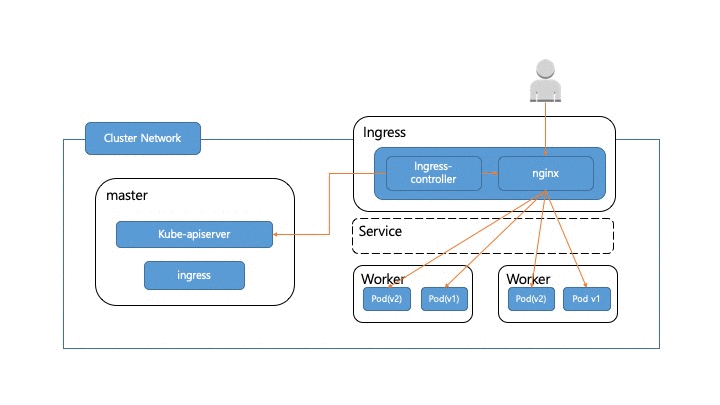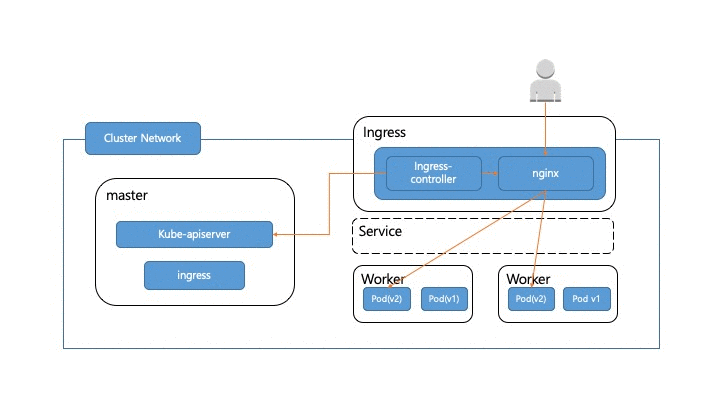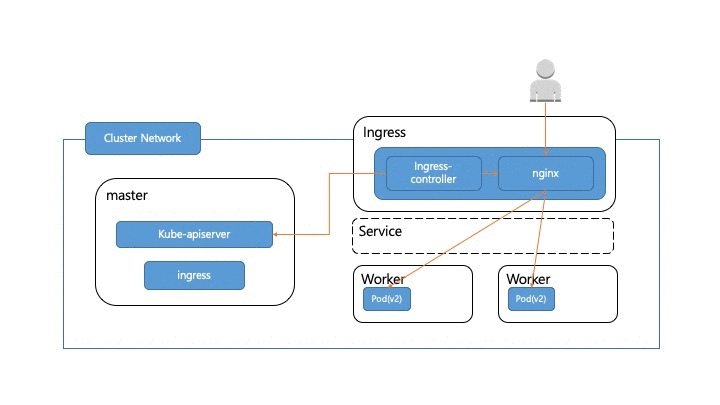
먼저 kubernetes로 트래픽이 들어오는 구조를 살펴보도록 하겠습니다. kubernetes클러스터 내부에 있는 pod까지 트래픽이 도달하는 경로는 대략 다음과 같습니다.
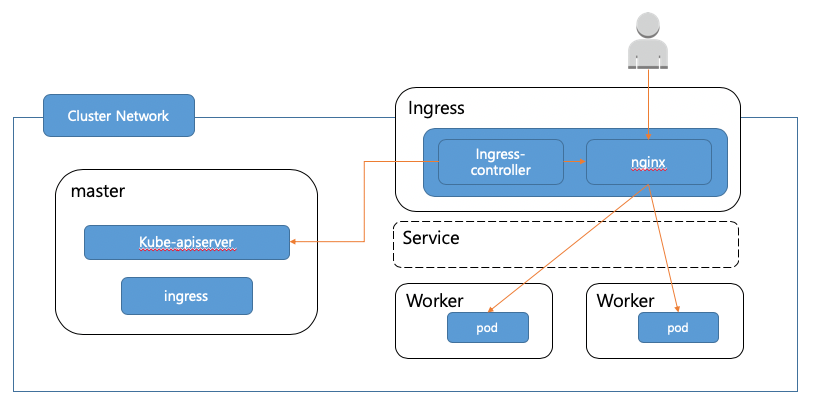
kubernetes는 별도의 클러스터 네트워크를 구성해서 이뤄지는 경우가 많기 때문에 외부에서 클러스터 내부에서 실행중인 pod에 접근하기 위해서는 인입되는 트래픽을 클러스터 내부까지 전달해줄 LB역할을 해줄 매개체가 필요한데요. AWS, GCP, Azure같은 Public cloud를 사용할때는 거기서 제공해주는 LB를 사용하면 되지만, 내부에 구축할때는 일반적으로 앞의 그림에 있는 ingress-controller를 사용합니다. ingress-controller에도 여러가지 종류가 있지만 이 글에서는 일반적인 nginx ingress controller를 기준으로 이야기하겠습니다. Kubernetes 내부에서 pod간 통신을 위해서는 중간에 service를 두고 통신하게 되는데요. ingress를 설정할때 역시 개별 pod들을 이용하는게 아니라 pod와 연결된 service를 설정하도록 되어 있습니다. 다음 ingress 설정을 보시면 serviceName으로 ingress를 통해서 연결하려는 서비스를 지정한 걸 확인할 수 있습니다.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- http:
paths:
- path: /testpath
backend:
serviceName: test
servicePort: 80
이렇게 설정되면 실제 nginx-ingress-controller는 이 service를 통해서 pod에 연결하는게 아니라 이 service에 연결된 pod의 정보를 가져와서 직접 nginx config로 설정하게 됩니다. 그래서 위의 그림에서는 service를 이용하긴하지만 직접 service를 거쳐서 통신하는건 아니라는 의미에서 service영역을 점선으로 표시했습니다.
kubernetes pod 배포시 기본 구조
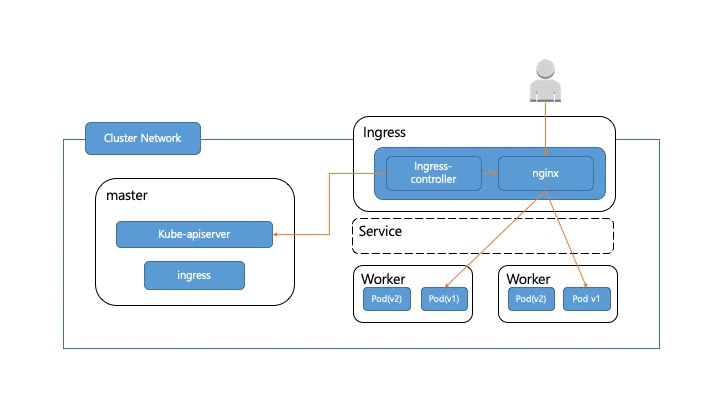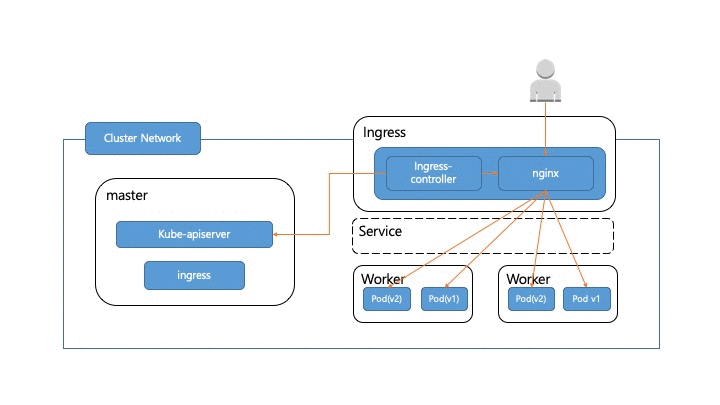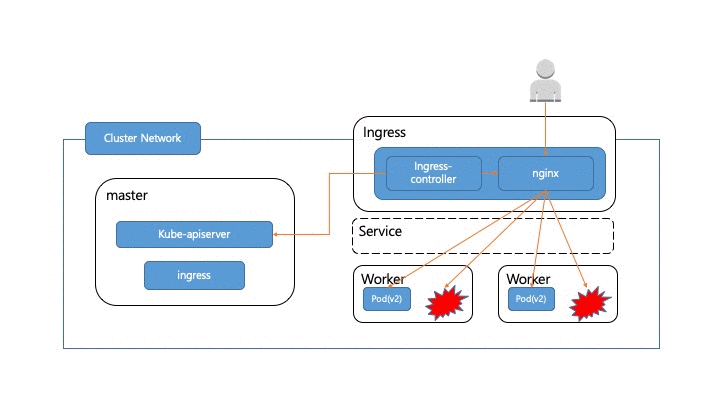
앞에서 서비스 트래픽이 실제 어떻게 pod까지 전달되는지 알아봤습니다. 이제 실서비스에서 트래픽이 흘러가고 있는 와중에 pod를 어떻게 무중단으로 배포할 수 있는지 알아보도록 하겠습니다. 우선 pod가 배포되면 pod 교체가 어떻게 일어나는지 살펴보도록 하겠습니다. 정상적인 경우라면 아래 그림처럼 새로운 pod(v2)가 생성되고 헬스체크가 성공한 후에 트래픽이 pod(v2)쪽으로 흘러가게 됩니다. 그 후에 pod(v1) 쪽으로 가던 트래픽이 제거된 후 pod(v1)이 제거 됩니다.
이 과정에서 고려해야 할 부분들이 몇 군데 있습니다.
kubernetes 배포시 고려해야할 컨테이너 구성
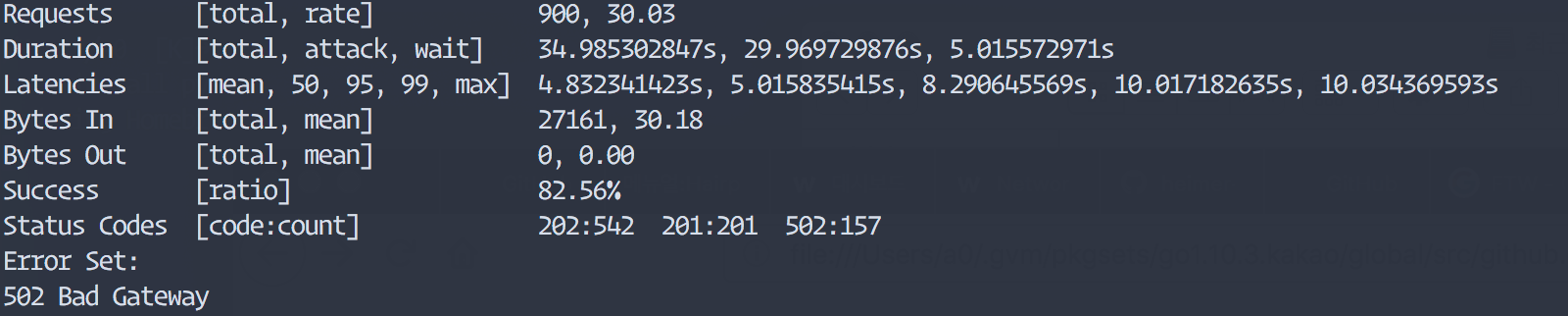
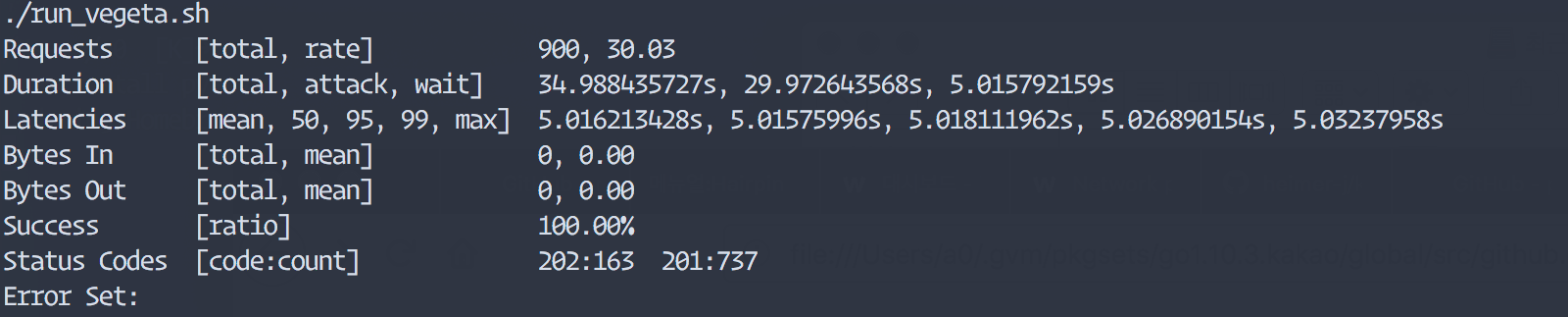
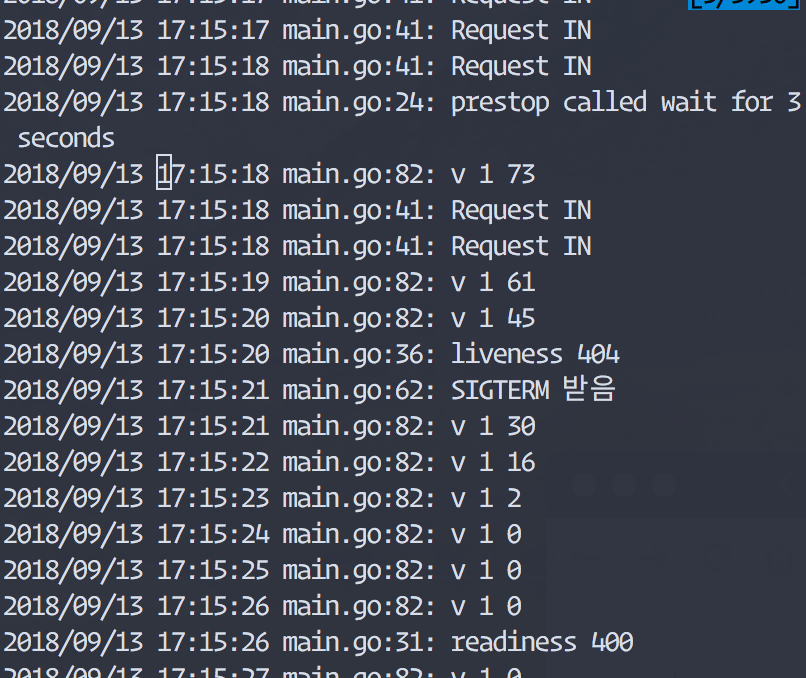
Kubernetes 가 대부분의 배포 절차를 잘 수행해 주지만 컨테이너 내부에서도 종료될때 graceful shutdown구현이 필요합니다. 새로운 pod가 실행되고 이전 pod를 종료할때 kubernetes에서 노드의 컨테이너를 관리하는 프로세스인 kubelet은 먼저 pod에 SIGTERM 신호를 보내게 됩니다. 컨테이너에서 SIGTERM을 받았을때 기존에 처리중이던 요청에 대한 처리를 완료하고 새로운 요청을 받지 않도록 개발되어 있어야 합니다. 그렇지 않으면 아래 그림처럼 트래픽은 아직 Pod(v1)쪽으로 가고 있는데 Pod(v1)이 종료되어 버려서 아직 ingress-controller의 설정이 갱신되기 전에 pod(v1)으로 가는 요청들은 에러를 내게 됩니다. kubelet에서 pod에 SIGTERM을 보낸후에 일정시간동안 graceful shutdown이 되지 않는다면 강제로 SIGKILL을 보내서 pod를 종료하게 됩니다. 이 대기 기간은 terminationGracePeriodSeconds 으로 설정해 줄 수 있고 기본 대기 시간은 30초 입니다.
SIGTERM 수신 뒤 즉시 종료 : 17.44% Request 502 error
SIGTERM 시그널 처리시 : 무중단 배포 가능
kubernetes 배포시 고려해야할 kubernetes 옵션
컨테이너가 SIGTERM을 고려해서 잘 만들어져 있다면 kubernetes에서 배포 과정에 어떤 옵션들을 활용할 수 있는지 살펴보겠습니다.
먼저 pod의 롤링업데이트를 위한 maxSurge와 maxUnavailable 설정 옵션입니다. deployment를 이용해서 배포할 때 maxSurge는 deployment에 설정되어 있는 기본 pod개수보다 여분의 pod가 몇개가 더 추가될 수 있는지를 설정할 수 있습니다. maxUnavailable는 업데이트하는 동안 몇 개의 pod가 이용 불가능하게 되어도 되는지를 설정하는데 사용됩니다. 이 두개의 옵션을 운영중인 서비스의 특성에 맞게 적절히 조절해 주어야지 항상 일정 개수 이상의 pod가 이용가능하게 되기 때문에 배포중 트래픽 유실이 없게 됩니다. 둘 다 한꺼번에 0으로 설정되면 pod가 존재하지 않는 경우가 발생하기 때문에 한꺼번에 0으로 설정할 수는 없습니다.
그 다음으로는 pod의 readinessProbe 설정입니다. kubernetes에서는 pod의 헬스체크를 확인하기 위해서 2가지 상태체크 옵션을 주고 있습니다. livenessProbe와 readinessProbe입니다. livenessProbe는 컨테이너가 살아 있는지 확인하는 역할을 하고 이 헬스체크가 실패하면 kubelet이 컨테이너를 죽이게 됩니다. 그리고 컨테이너의 restart policy에 따라 컨테이너가 재시작됩니다. 무중단 배포에서 신경써서 봐야할 설정은 readinessProbe입니다. readinessProbe는 실제로 컨테이너가 서비스 요청을 처리할 준비가 되었는지를 확인하는데 사용됩니다. readinessProbe가 ok상태여야지 이 pod와 연결된 service에 pod의 ip가 추가되고 트래픽을 받을 수 있게 됩니다. 자바 프로세스 같은 경우는 프로세스가 올라와서 livenessProbe가 ok상태가 되더라도 초기화 과정이 오래 걸리기 때문에 readinessProbe를 따로 설정하지 않을때에 아직 준비되지 않은 컨테이너로 요청이 가서 응답을 제대로 하지 못하고 실패할 수 있습니다. 그런 경우를 방지하기 위해서 실제 서비스가 준비된 상태인지를 확인할 수 있는 readinessProbe를 잘 설정해 주어야 합니다.
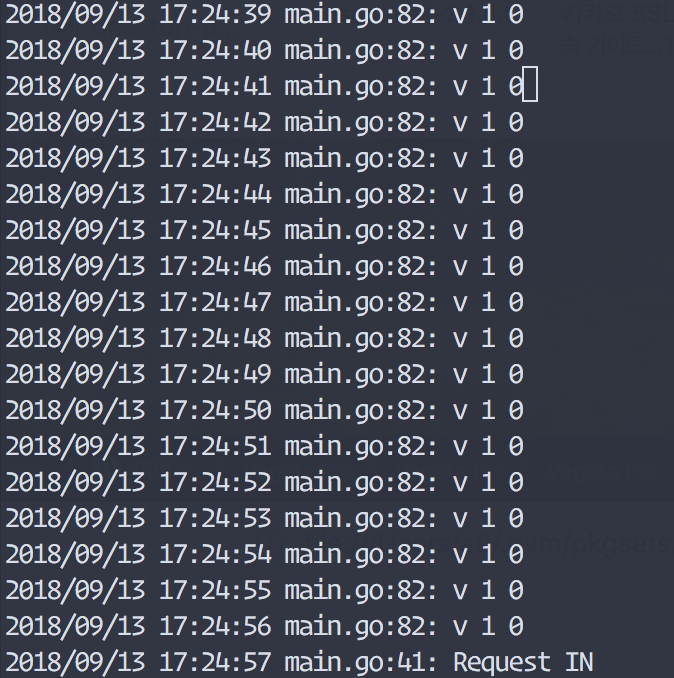
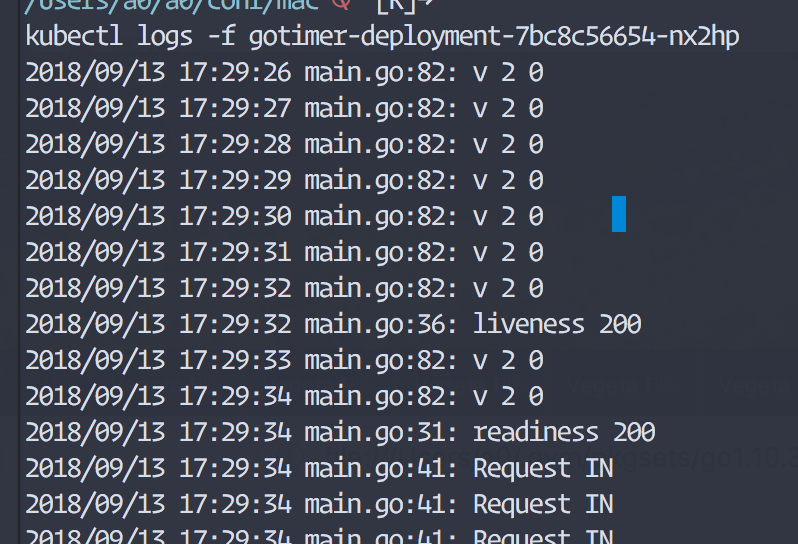
경우에 따라서는 앱 자체가 readinessProbe를 설정해주기 어려운 상황일 수도 있습니다. 그럴때는 .spec.minReadySeconds 옵션을 이용하면 어느정도 readinessProbe와 비슷한 효과를 낼 수 있습니다. .spec.minReadySeconds은 pod의 status가 ready가 될때까지의 최소대기시간입니다. 그래서 pod가 실행되고나서 .spec.minReadySeconds에 설정된 시간동안은 트래픽을 받지 않습니다. 그렇기 때문에 readinessProbe를 설정하기 어렵고 초기화 시간이 오래 걸리는 컨테이너에 대해서 사용하면 컨테이너가 준비될때까지 일정시간동안 트래픽을 받지않고 대기할 수 있기 때문에 유용하게 사용할 수 있습니다. 하지만, readinessProbe가 완료되면 .spec.minReadySeconds에 설정된 시간이 아직 남아 있더라고도 무시되고 트래픽을 보내게 됩니다. .spec.minReadySeconds의 기본값은 0입니다.
MinReadySeconds 옵션 : pod status 가 ready 로 업데이트 될 때 까지 최소 대기 시간, 그 전까지 서비스에서 트래픽 받지 않음
Readiness Check 가 완료 되면 MinReadySeconds 설정은 무시된다.
pod가 종료될때 graceful shutdown을 구현하지 못하는 경우도 있을 수 있습니다. 앱이 사용하는 언어나 프레임워크가 지원하지 않는 경우도 있고, 오래된 레거시라서 앱을 수정하지 못한채 컨테이너로 올려야되는 경우도 있을 수 있습니다. 이런 경우에는 prestop hook을 이용할 수 있습니다. kubernetes에서는 pod 라이프사이클중에 hook을 설정할 수 있습니다. pod가 실행되고난 직후 실행하는 poststart hook과 pod가 종료되기 직전 실행되는 prestop hook입니다. prestop 훅은 pod에 SIGTERM을 보내기 전에 실행되기 때문에 prestop을 이용하면 앱과 별개로 graceful shutdown의 효과를 내게 할 수도 있습니다. Prestop 훅의 실행이 완료되기 전까지는 컨테이너에 SIGTERM을 보내지 않기 때문에 앱의 구현과는 별개로 종료되기 전에 대기시간을 주는 것도 가능해 지게 됩니다. 하지만 이렇게 prestop 훅으로 대기시간을 주더라도 terminationGracePeriodSeconds 시간을 초과한다면 프로세스 종료가 일어날 수 있으니 염두에 두고 사용해야 합니다.
위 내용은 카카오 사내 컨테이너 오케스트레이션 서비스인 DKOS를 운영하던 중 많이 나오는 문의사항을 토대로 배포시 고려해야 할 kubernetes 구조와 옵션 등을 살펴봤습니다. DKOS는 클라우드디플로이셀의 hardy.jung, dennig.hong, scott.vim, heimer.j등이 함께 운영해오고 있습니다.