용어 정리
이 설명에서는 인덱스의 정렬 순서와 데이터 읽기 순서 등 방향에 대한 단어들이 혼재하면서, 여러 가지 혼란을 초래하기 쉬운 설명들이 있을 것으로 보인다. 그래서 우선 표준 용어는 아니지만, 나름대로 몇 개 단어들에 대해서 개념을 정립하고 그 단어를 번역 없이 영어로 그대로 표기하도록 하겠다.
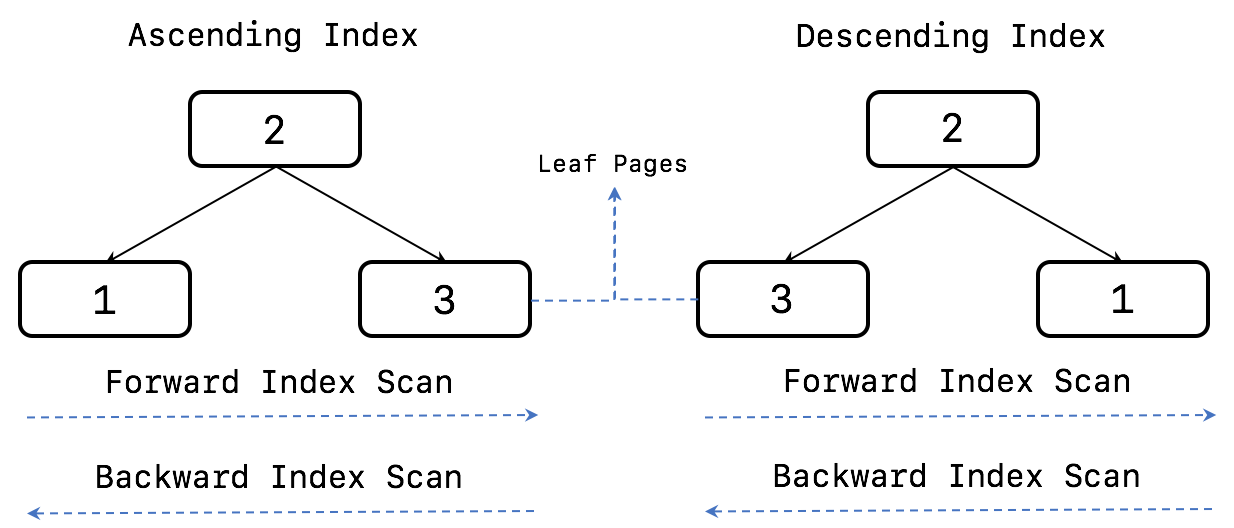
Ascending index: 작은 값의 인덱스 키가 B-Tree의 왼쪽으로 정렬된 인덱스Descending index: 큰 값의 인덱스 키가 B-Tree의 왼쪽으로 정렬된 인덱스Forward index scan(Forward scan) : 인덱스 키의 크고 작음에 관계없이 인덱스 리프 노드의 왼쪽 페이지부터 오른쪽으로 스캔Backward index scan(Backward scan) : 인덱스 키의 크고 작음에 관계없이 인덱스 리프 노드의 오른쪽 페이지부터 왼쪽으로 스캔
Descending index 지원
MySQL 4.x 버전부터 Feature Request로 등록되어 있던 “Descending index” 기능이 드디어 MySQL 8.0에 도입되었다.
MySQL 8.0부터는 이제 아래와 같이 역순으로 정렬되는 인덱스(Descending index)를 생성할 수 있게 되었으며, 필요에 따라서 적절히 정순(ORDER BY ASC)과 역순(ORDER BY DESC)을 혼합해서 정렬하는 작업을 인덱스를 이용할 수 있게 된 것이다.
CREATE TABLE tb_wow (
uid BIGINT PRIMARY KEY,
age SMALLINT,
score SMALLINT,
INDEX ix_score_age (score DESC, age ASC)
);
SELECT * FROM tb_wow ORDER BY score ASC, age DESC;
SELECT * FROM tb_wow ORDER BY score DESC, age ASC ;
아마도 MySQL 8.0 이전에도 Descending index가 지원되었다고 생각했을 수도 있는데, MySQL 8.0 이전에는 문법만 지원되고 실제 Descending index가 지원되는 것은 아니었다. 또한 Ascending index를 Forward scan하는 것과 Backward scan하는 것만으로 Descending index의 요건을 충분히 만족한다고 생각할 수도 있지만, 실제 그렇지 못한 경우도 많다.
MySQL 8.0에 도입된 Descending index가 필요한 가장 큰 이유는 이미 살펴본 예제와 같이 정순(ORDER BY ASC)과 역순(ORDER BY DESC) 정렬을 섞어서 여러 컬럼으로 정렬하는 경우일 것이다. 그런데 Descending index가 필요한 이유가 오직 이것뿐일까?
Descending index를 사용해야 하는 또 다른 이유
MySQL 8.0 이전 버전을 사용하면서 역순 정렬이 필요한 경우에는, 크게 성능에 대한 고려 없이 지금까지 Ascending index를 생성하고 “ORDER BY index_column DESC” 쿼리로 인덱스를 Backward scan으로 읽는 실행 계획을 사용해왔다. 이제 Ascending index를 Forward scan하는 경우와 Backward scan하는 경우의 성능 비교를 간단히 예제로 한번 살펴보자.
우선 아래와 같이 information_schema.COLUMNS 테이블의 레코드를 복사해서 대략 1천2백여만 건의 레코드를 가지는 테이블을 만들어 보자.
CREATE TABLE t1 (
tid INT NOT NULL AUTO_INCREMENT,
TABLE_NAME VARCHAR(64),
COLUMN_NAME VARCHAR(64),
ORDINAL_POSITION INT,
PRIMARY KEY(tid)
) ENGINE=InnoDB;
INSERT INTO t1 SELECT NULL, TABLE_NAME, COLUMN_NAME, ORDINAL_POSITION FROM information_schema.COLUMNS;
INSERT INTO t1 SELECT NULL, TABLE_NAME, COLUMN_NAME, ORDINAL_POSITION FROM t1; -- // 12번 실행
mysql> SELECT COUNT(*) FROM t1;
+----------+
| COUNT(*) |
+----------+
| 12619776 |
+----------+
이제 이 테이블을 풀 스캔 하면서 정렬만 수행하는 쿼리를 아래와 같이 한번 실행해보자. 아래 두 쿼리는 테이블의 프라이머리 키를 Forward scan 또는 Backward scan으로 읽어서 마지막 레코드 1건만 반환하게 된다. 첫번째 쿼리는 tid 컬럼의 값이 가장 큰 레코드 1건을 그리고 두번째 쿼리는 tid 컬럼의 값이 가장 작은 레코드 1건을 반환하게 된다. 하지만 LIMIT .. OFFSET .. 부분의 쿼리로 인해서, 실제 MySQL 서버는 테이블의 모든 레코드를 스캔해야만 한다. (이 쿼리는 모든 레코드를 스캔하는 작업은 하지만, 화면에는 레코드 1건만 출력하려고 LIMIT .. OFFSET .. 옵션을 추가한 것임)
SELECT * FROM t1 ORDER BY tid ASC LIMIT 12619775,1;
SELECT * FROM t1 ORDER BY tid DESC LIMIT 12619775,1;
위 두 쿼리의 실행 결과는 어떤 차이를 보여줄지 먼저 한번 예측해보자. 지금까지는 많은 사용자들이 두 쿼리가 동일한 실행 시간을 보여줄 것이라 믿어 의심치 않았을 것이다. 당연히 그렇게 작동해야 하니까 고려 대상조차 아니었다.
mysql> SELECT * FROM t1 ORDER BY tid ASC LIMIT 12619775,1;
1 row in set (4.14 sec)
1 row in set (4.15 sec)
1 row in set (4.15 sec)
1 row in set (4.14 sec)
1 row in set (4.15 sec)
mysql> SELECT * FROM t1 ORDER BY tid DESC LIMIT 12619775,1;
1 row in set (5.35 sec)
1 row in set (5.35 sec)
1 row in set (5.35 sec)
1 row in set (5.36 sec)
1 row in set (5.35 sec)
테스트 환경 (CPU Bound 테스트)
- CPU : Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz (x 24)
- MEMORY : 64GB
- DISK : NVME SSD
- TABLE SIZE (Disk) : 883MB
- MySQL configuration
- innodb_buffer_pool_instances=2
- innodb_buffer_pool_size=30G
- innodb_adaptive_hash_index=OFF
1천2백여만건을 스캔하는데, “1.2초 정도의 차이쯤이야!!”라고 생각할 수도 있다. 하지만 비율로 따져보면, 역순 정렬 쿼리가 정순 정렬 쿼리보다 28.9% 더 시간이 걸리는 것을 확인할 수 있다. 하나의 인덱스를 정순으로 읽느냐 또는 역순으로 읽느냐에 따라서 이런 차이가 발생한다는 것은 쉽게 이해하기 어렵다.
Backward index scan이 느린 이유
MySQL 서버의 InnoDB 스토리지 엔진에서 (많은 사용자들이 이미 잘 알고 있듯이) Forward & Backward index scan 페이지(블록) 간의 양방향 연결 고리(Double linked list)를 통해서 전진(Forward)하느냐 후진(Backward)하느냐의 차이만 있다. 이것만 보면 Forward와 Backward index scan의 성능 차이는 이해되지 않는다.
실제 InnoDB에서 Backward index scan이 Forward index scan에 비해서 느릴 수밖에 없는 2가지 이유를 가지고 있다.
- 페이지 잠금이
Forward index scan에 적합한 구조 - 페이지 내에서 인덱스 레코드는 단방향으로만 연결된 구조 (Forwarded single linked link)
1. 페이지 잠금이 Forward index scan에 적합한 구조
InnoDB의 페이지 잠금 방식은 Forward index scan을 중심으로 구현되어 있는데, Forward index scan으로 인덱스 리프 페이지를 읽을 때는, 아래 코드 샘플과 같이 페이지의 잠금을 획득할 때에는 Forward scan 순서대로 잠금을 걸고 다시 잠금을 해제하게 된다.
void
btr_pcur_move_to_next_page(
/*=======================*/
btr_pcur_t* cursor, /*!< in: persistent cursor; must be on the
last record of the current page */
mtr_t* mtr) /*!< in: mtr */
{
// ... skip ...
page = btr_pcur_get_page(cursor);
next_page_no = btr_page_get_next(page, mtr);
// ... skip ...
buf_block_t* block = btr_pcur_get_block(cursor);
// 다음 페이지(next page)를 찾아서, 잠금 획득
next_block = btr_block_get(
page_id_t(block->page.id.space(), next_page_no),
block->page.size, mode,
btr_pcur_get_btr_cur(cursor)->index, mtr);
next_page = buf_block_get_frame(next_block);
// ... skip ...
// 다음 페이지(next page) 잠금 획득후, 현재 페이지(이전 페이지)의 잠금을 해제
btr_leaf_page_release(btr_pcur_get_block(cursor), mode, mtr);
// ... skip ...
}
이제 Backward index scan시에 페이지 잠금을 획득하는 코드 샘플을 한번 살펴보자.
void
btr_pcur_move_backward_from_page(
/*=============================*/
btr_pcur_t* cursor, /*!< in: persistent cursor, must be on the first
record of the current page */
mtr_t* mtr) /*!< in: mtr */
{
// ... skip ...
// 커서의 현재 상태 백업
btr_pcur_store_position(cursor, mtr);
mtr_commit(mtr); // Mini-transaction 커밋 (페이지 잠금 해제)
mtr_start(mtr); // Mini-transaction 시작
// BTR_SEARCH_PREV 모드로 커서 복구
btr_pcur_restore_position(latch_mode2, cursor, mtr);
page = btr_pcur_get_page(cursor);
prev_page_no = btr_page_get_prev(page, mtr);
/* For intrinsic table we don't do optimistic restore and so there is
no left block that is pinned that needs to be released. */
if (!dict_table_is_intrinsic(
btr_cur_get_index(btr_pcur_get_btr_cur(cursor))->table)) {
if (prev_page_no == FIL_NULL) {
} else if (btr_pcur_is_before_first_on_page(cursor)) {
prev_block = btr_pcur_get_btr_cur(cursor)->left_block;
// 불필요시 현재 페이지 잠금 해제
btr_leaf_page_release(btr_pcur_get_block(cursor),
latch_mode, mtr);
page_cur_set_after_last(prev_block,
btr_pcur_get_page_cur(cursor));
} else {
/* The repositioned cursor did not end on an infimum
record on a page. Cursor repositioning acquired a latch
also on the previous page, but we do not need the latch:
release it. */
prev_block = btr_pcur_get_btr_cur(cursor)->left_block;
// 불필요시 이전 페이지(Backward page) 잠금 해제
btr_leaf_page_release(prev_block, latch_mode, mtr);
}
}
cursor->latch_mode = latch_mode;
cursor->old_stored = false;
}
대략 코드를 읽어보면, (100% 이해는 어렵더라도) 대략 Backward index scan으로 이전 페이지로 넘어가는 과정은 아래와 같은 처리가 발생하는 것을 알 수 있다.
- 커서의 상태를 저장하고 내부 미니 트랜잭션을 커밋해서 미니 트랜잭션 버퍼를 글로벌 리두 로그 버퍼로 복사
- 미니 트랜잭션을 재시작
- 커서의 상태를 다시 복구 (이 과정에서 현재 블록이 이동되는 것을 막기 위해서 pinning을 하고 필요에 따라서 현재 블록과 이전 블록(Backward block)의 잠금을 획득)
InnoDB의 B-Tree 리프 페이지는 Double linked list로 연결되어 있기 때문에, 사실 어느 방향이든지 이동 자체는 차이가 없다. 하지만 InnoDB 스토리지 엔진에서는 페이지 잠금 과정에서 데드락을 방지하기 위해서 B-Tree의 왼쪽에서 오른쪽 순서(Forward)로만 잠금을 획득하도록 하고 있다. 그래서 Forward index scan에서는 다음 페이지 잠금 획득이 매우 간단하지만, Backward index scan에서 이전 페이지 잠금을 획득하는 과정은 상당히 복잡한 과정을 거치게 된다.
이런 차이로 인서 많은 페이지를 스캔해야 하는 Index scan에서는 잠금 획득으로 인한 쿼리 처리 지연이 발생하게 된다.
2. 페이지 내에서 인덱스 레코드는 단방향으로만 연결된 구조
InnoDB 스토리지 엔진이 특정 레코드를 검색할 때, B-Tree를 이용해서 검색 대상 레코드(인덱스 엔트리)가 저장된 페이지(Block)까지는 검색할 수 있다. 하지만 그 페이지 내에도 수많은 레코드가 저장되어 있는데, 일반적으로 20바이트 키를 저장하는 인덱스 페이지(16K)라면, 대략 600여개 이상의 레코드가 저장될 수 있다. InnoDB 스토리지 엔진이 600여개 레코드를 하나씩 다 순차적으로 비교한다면 레코드 검색이 상당히 느릴 것이다. 그래서 InnoDB 스토리지 엔진은 하나의 페이지내에서 순차적으로 정렬된 레코드 4~8개 정도씩을 묶어서 대표 키(가장 큰 인덱스 엔트리 키 값)를 선정한다. 그리고 이 대표 키들만 모아서 별도의 리스트를 관리하는데, 이를 페이지 디렉토리(Page directory)라고 한다. 아래 그림은 “Jeremy Cole”이 그린 “InnoDB 자료 구조“중에서 “InnoDB page directory” 그림을 캡처한 것이다. 이미 충분히 이해하기 쉽도록 그려져 있어 그대로 차용하고자 한다.
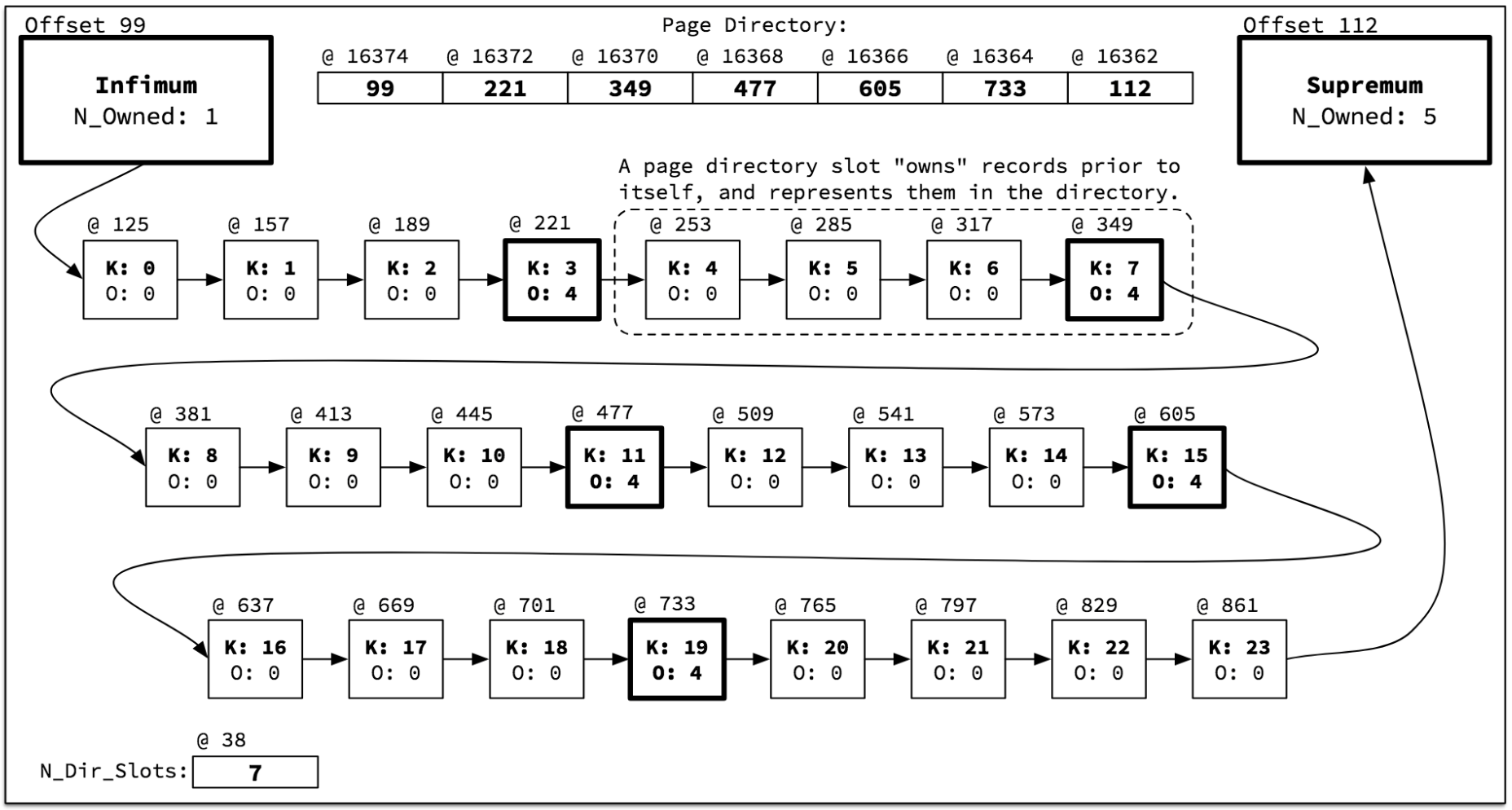
InnoDB 스토리지 엔진은 하나의 페이지에서 특정 키 값을 검색할 때 Page directory를 이용해서 바이너리 서치(Binary search) 방식으로 검색 대상 키를 포함하는 대표 키를 검색한다. 그리고 대표 키를 찾으면 그때부터는 인덱스 키 값 순서대로 연결된 Linked list를 이용해서 대상 레코드를 검색하게 된다.
그런데 Double linked list로 연결된 B-Tree의 리프 페이지 구조와는 달리, 페이지 내부의 레코드(인덱스 엔트리)들은 Single linked list 구조로 구성되어 있다. Single linked list는 Ascending index에서는 키 값이 오름차순으로 정렬되어서 Linked list로 구성되는 것이다. 만약 Descending index라면 키 값이 내림차순으로 정렬되어서 Linked list 구성될 것이다. 그래서 Ascending index에서 Forward index scan은 Linked list를 그대로 따라가기만 하면 되지만, Backward index scan은 그렇게 간단하지 않다.
아래 코드 샘플은 Forward index scan을 할 때 하나의 페이지에서 Page directory를 이용해서 다음 레코드를 찾아오는 방법을 보여주고 있다.
UNIV_INLINE
const rec_t*
page_rec_get_next_low(
/*==================*/
const rec_t* rec, /*!< in: pointer to record */
ulint comp) /*!< in: nonzero=compact page layout */
{
// ... skip ...
page = page_align(rec);
offs = rec_get_next_offs(rec, comp);
// ... skip ...
return(page + offs);
}
Forward index scan은 단순히 Linked list만 따라가면 되기 때문에 코드 역시 매우 간단하다. 이제 Backward index scan의 코드 샘플을 한번 비교해보자.
UNIV_INLINE
const rec_t*
page_rec_get_prev_const(
/*====================*/
const rec_t* rec) /*!< in: pointer to record, must not be page
infimum */
{
// ... skip ...
page = page_align(rec);
// Page directory를 검색해서, 레코드를 저장하고 있는 슬롯(Directory)을 검색
slot_no = page_dir_find_owner_slot(rec);
// 현재 레코드가 저장된 슬롯의 이전 슬롯(slot_no-1)을 가져와서
slot = page_dir_get_nth_slot(page, slot_no - 1);
// 해당 슬롯의 대표 레코드를 가져온다
rec2 = page_dir_slot_get_rec(slot);
if (page_is_comp(page)) {
// ... skip ...
} else {
while (rec != rec2) {
prev_rec = rec2;
// 다음 레코드가 자기 자신일 때까지 loop를 실행
// 자기 자신 레코드를 찾으면, 그 이전 레코드가 이전 레코드이므로
rec2 = page_rec_get_next_low(rec2, FALSE);
}
}
// ... skip ...
// 검색된 이전 레코드 리턴
return(prev_rec);
}
사실 코드 자체는 많이 복잡하지 않지만, Page directory별로 4~8개 정도의 레코드(인덱스 키 엔트리)가 저장되므로 while loop을 평균적으로 2~4번 정도씩 실행해야 이전 레코드(Backwrad index scan)를 찾을 수 있는 것이다.
Backward index scan의 서비스 영향도
이로써 Backward index scan이 Forward index scan보다 느린 이유를 알게 되었다. 그렇다면 실제 Backward index scan을 사용하면 서비스가 엄청나게 느려지는 것일까? Forward index scan과 Backward index scan의 실제 서비스 영향도는 일반적으로 그렇게 크지 않았다. 아주 랜덤한 키 값으로 검색해서 Index range scan을 실행하는 경우 대략 아래 그래프와 같이 10% 정도의 쿼리 스루풋 차이를 보였으며, CPU 사용량의 차이는 미미했다 (Test thread를 16개 정도로 안정적인 쿼리 처리가 가능한 상황에서의 테스트 결과).
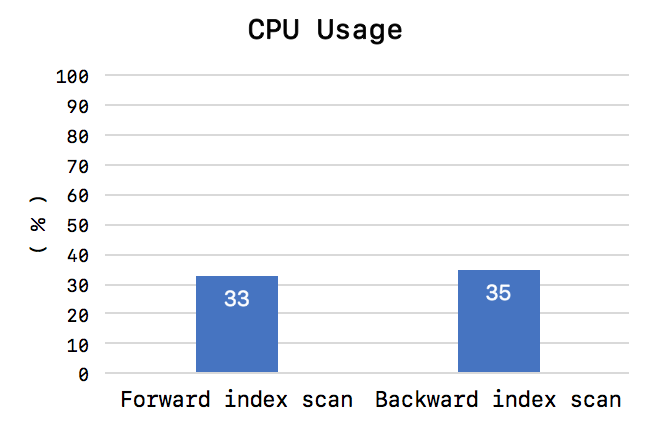
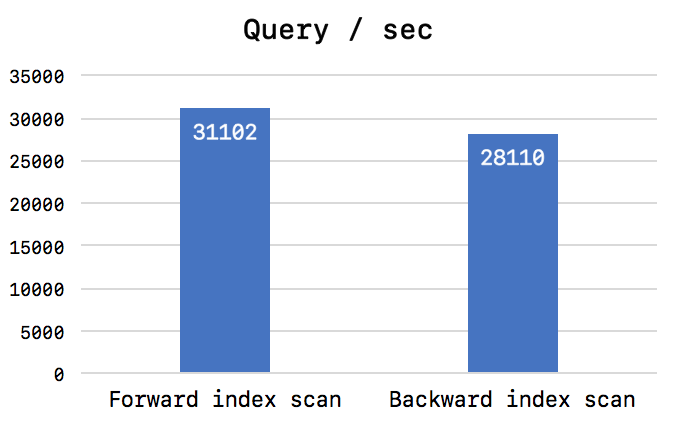
Forward index scan
- set @random_tid=floor(rand()*12994454);
- select tid from t1 where tid>=@random_tid order by tid ASC limit 50;
Backward index scan
- set @random_tid=floor(rand()*12994454);
- select tid from t1 where tid<=@random_tid order by tid DESC limit 50;
하지만 정렬된 Index의 특정 부분(인덱스의 앞부분 또는 끝부분)을 집중적으로 읽는 경우, 44% 정도의 스루풋 차이를 보이며 CPU 사용량도 큰 차이를 보였다.
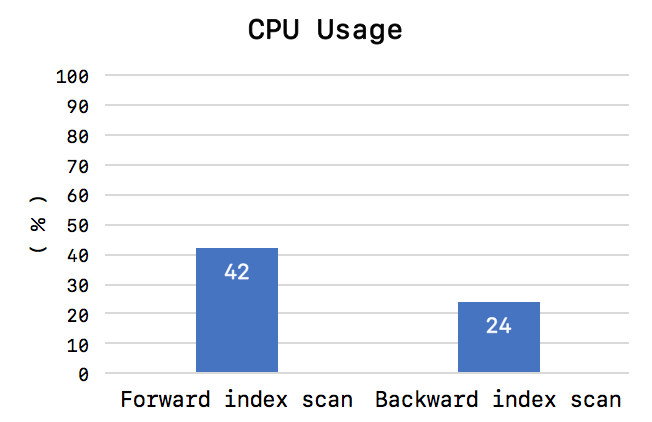
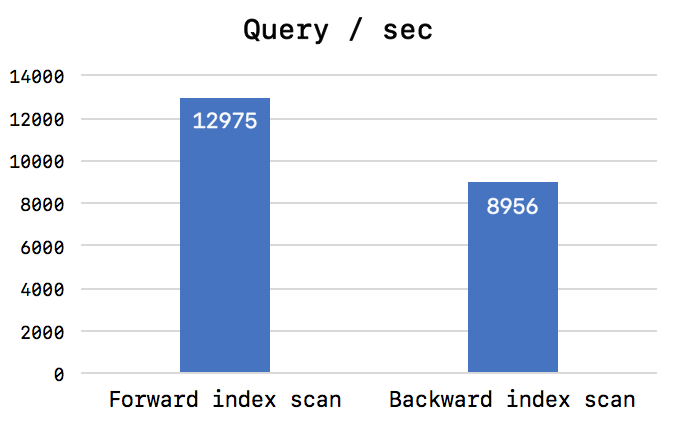
Forward index scan
- select tid from t1 order by tid ASC limit 1000;
Backward index scan
- select tid from t1 order by tid DESC limit 1000;
첫번째 테스트에서는 매번 쿼리가 실행될 때마다 인덱스 스캔 위치를 랜덤하게 선택하도록 해서, 실제 각 쓰레드간의 페이지 잠금 경합이 그다지 심하지 않았던 것이다. 그리고 인덱스를 Backward scan하는 데 추가로 더 걸린 시간은 쿼리의 처리 시간에 그다지 크게 영향을 미치지 않았던 것이다. 그런데 이번 테스트 케이스(두번째 테스트 케이스)에서는 유입되는 모든 쿼리가 동일 페이지에 집중되는 상황인데, 이때에는 쿼리를 실행중인 쓰레드들끼리 경합을 하면서 아주 짧은 페이지 잠금 시간이 더 길어지는 효과를 내게 된 것이다. 그래서 쿼리의 Ascending index scan보다 Descending index scan이 훨씬 더 많은 쿼리 시간이 걸리게 된 것이다.
두번째 테스트 케이스에서는 1000건의 레코드를 조회(LIMIT 1000)하도록 했는데, 이 건수가 하나의 페이지에 저장된 레코드 건수보다 크면 Ascending과 Descending index scan의 성능 차이가 커졌으며, 조회 건수가 페이지에 저장된 레코드 건수보다 적으면 Ascending과 Descending index scan의 성능 차이는 줄어들었다. 즉 성능 차이에 영향을 미치는 2가지 구조적 이유 중에서, 페이지 잠금이 Forward index scan에 적합한 구조가 더 크게 영향을 미치는 것으로 보인다.
사용자에게 일반적으로 노출되는 잠금(Table & Row lock, …) 이외에도 InnoDB 스토리지 엔진에서는 내부적으로 페이지의 레코드를 접근할 때마다, 페이지에 대해서 잠금을 걸어야 한다. 이때 InnoDB 스토리지 엔진은 RW-lock(Semaphore)이 아닌 Mutex를 사용하기 때문에 읽기 쿼리와 쓰기 쿼리뿐만 아니라 읽기 쿼리들끼리도 페이지 잠금을 점유하기 위해서 경쟁해야 하기 때문에, 동시 쓰레드가 많아지면 많아질수록 성능 영향도는 더 커지게 되는 결과를 만들게 될 것으로 보인다.
참고로, 테이블의 데이터 파일을 구성하는 B-Tree의 각 페이지에 저장된 레코드 건수가 성능을 영향을 미치게 되는데, 이 테스트를 위한 테이블의 각 페이지에 저장된 레코드 건수는 아래와 같았다.
+-------+-------+-------+-------+-------+---------+--------------+ | page | index | level | data | free | records | min_key | +-------+-------+-------+-------+-------+---------+--------------+ | 4 | 52 | 0 | 7443 | 8737 | 146 | tid=1 | | 5 | 52 | 0 | 15035 | 1079 | 282 | tid=147 | | 6 | 52 | 0 | 15084 | 1036 | 271 | tid=429 | ... | 55354 | 52 | 0 | 15083 | 1057 | 229 | tid=12993805 | | 55355 | 52 | 0 | 15095 | 1049 | 222 | tid=12994034 | | 55356 | 52 | 0 | 13049 | 3107 | 199 | tid=12994256 | +-------+-------+-------+-------+-------+---------+--------------+
Ascending vs Descending index의 선택 기준
일반적으로 인덱스를 ORDER BY ... DESC하는 쿼리가 소량의 레코드를 드물게 실행되는 경우라면, Descending index를 굳이 고려할 필요는 없어 보인다.
SELECT * FROM tab WHERE userid=? ORDER BY score DESC LIMIT 10;
예를 들어서 아래와 같은 쿼리인 경우, 아래 2가지 인덱스 모두 적절한 선택이 될 수 있다.
- Ascending index : INDEX (userid ASC, score ASC)
- Descending index : INDEX (userid DESC, score DESC)
하지만 위 쿼리가 조금 더 많은 레코드를 빈번하게 실행된다면, Ascending index보다는 Descending index가 더 효율적이라고 볼 수 있다. 또한 많은 쿼리가 인덱스의 앞쪽만 또는 뒤쪽만 집중적으로 읽어서 인덱스의 특정 페이지 잠금이 병목 지점이 될 것으로 예상된다면, 적절히 Descending index를 생성하는 것이 경합 감소에 도움이 될 것으로 보인다.
물론 ASC와 DESC 정렬을 혼합해서 동시에 사용하는 쿼리라면, 당연히 ASC와 DESC를 섞어서 인덱스를 생성해야 하므로, 고민할 필요 없이 쿼리의 정렬 조건에 맞게 인덱스를 생성하면 될 것으로 보인다.
그리고 Ascending index와 Descending index의 선택은 MySQL 서버가 CPU Bound로 쿼리를 처리할 때의 이야기이다. 만약 MySQL 서버가 데이터를 읽기 위해서 매번 Disk를 읽어야 한다면, Ascending index나 Descending index의 구조적 장단점은 Disk 반응 속도(Latency)에 이미 상쇄되어 버리기 때문에 그다지 쿼리 처리상 성능 영향 요소가 아니라고 볼 수 있다.