Overview
웹 서비스의 규모가 커지고 이용자의 수가 늘어날수록 서비스 제공자는 scalability 이슈에 직면합니다. 그중에서도 실제 ‘로딩 속도’의 차이를 느끼게 해 주고 트래픽의 대부분을 차지하는 정적 컨텐츠의 신속한 제공은 서비스 품질을 좌우하는 중요한 요소가 되곤 합니다.
이런 수많은 컨텐츠들(Javascript, css, image 등)을 빠르게 제공하기 위해 클라이언트와 서버 사이에 위치하며 컨텐츠를 임시로 저장하는 Middlebox를 웹 캐시(web cache)라고 합니다. 웹 캐시의 기능은 Apache Traffic Server, Nginx, Squid와 같은 어플리케이션에서 지원하고 있으며, 대량의 컨텐츠를 처리하기 위한 전용 하드웨어 형태의 상용 솔루션도 있습니다.
본 포스트에서는 카카오에서 자체적으로 개발하여 운영 중인 웹 캐시, Wcache에 대한 간략한 소개를 진행하고 올해 상반기에 진행되었던 대대적인 구조 개편 내역을 다음 포스트에 설명하고자 합니다.
Part 1: 분산 웹 캐시, Wcache
개발 배경 및 기본적인 기능
기존에 웹 캐시로 사용되던 상용 솔루션의 문제점은 아래와 같았습니다.
- 장비 대수가 증가함에 따라 늘어나는 라이센스 비용.
- 버그 수정 및 지원의 어려움.
- 기능 개선이 불가능하거나 / 느리다.
이런 문제점은 점점 늘어나는 서비스들을 위한 기능을 추가하거나 장애 대응 및 트래픽 확장 시 걸림돌이 되었고, 자체적인 솔루션을 개발하는 계기가 되었습니다. C 언어로 구현된 Wcache는 범용 하드웨어(x86)의 자원을 최대한 활용하면서도 안정적인 성능을 낼 수 있도록 하였으며(multi-thread, I/O multiplexing, Direct Memory Access), HTTP 표준을 준수하는 캐시 정책, 컨텐츠 퍼지 및 Reverse / Forward HTTP Proxy의 기본적인 기능(HTTP message control, access log, access control, DNS caching 등)을 지원합니다.
저장 구조
웹 캐시의 성능은 보통 저장장치의 I/O 속도에 의해 좌우됩니다.1 특히 일정 수준의 캐시 hit율을 보장하기 위해 수십~수백 GB의 캐시 용량이 필요한 경우에는 디스크에 얼마만큼 안정적이고 효율적으로 컨텐츠를 저장하고 읽어오는가에 따라 성능이 크게 차이 날 수 있습니다.
컨텐츠 별로 파일을 만들어 저장하는 방식은 다수의 컨텐츠를 저장할 때 일반적인 범용 파일 시스템(ext3, ext4 등)상에서 많은 문제를 일으킵니다. 하나의 디렉토리에 많은 파일을 저장하기 힘들뿐더러, 다수의 디렉토리를 만들면 디스크 및 커널 메모리의 inode 캐시 낭비를 일으킵니다. 또한, 파일 개수가 많아질수록 접근 속도도 느려지고 용량 확보를 위해 오래된 컨텐츠를 삭제할 때에도 수많은 I/O가 발생하게 됩니다. 용량 활용 측면에서도 기본 파일 시스템 블럭 단위가 4KB이기 때문에 4KB 미만의 컨텐츠가 다수 존재할 경우 심한 용량 낭비를 유발합니다.
이러한 문제 때문에 Wcache에서는 독자적인 저장 구조를 만들어 컨텐츠 저장에 활용하였습니다. 먼저 컨텐츠 데이터가 저장되는 디스크에는 미리 일정한 크기(디스크 크기에 따라 64MB ~ 10GB)의 BigFile들을 여러 개 생성해 두어 컨텐츠를 저장할 공간을 확보해 둡니다. 이는 디스크가 연속된 영역에 순차적으로 데이터를 쓸 수 있도록 해줍니다. 추가로, 디스크 쓰기 작업 횟수를 줄이기 위해 BigFile 내부를 ‘block’이라는 세부 구조로 나누어 캐시가 되는 컨텐츠를 바로 저장하지 않고 메모리에 적재 후 block 단위로만 디스크에 쓰는 방식을 취하여 성능 향상을 이끌었습니다.
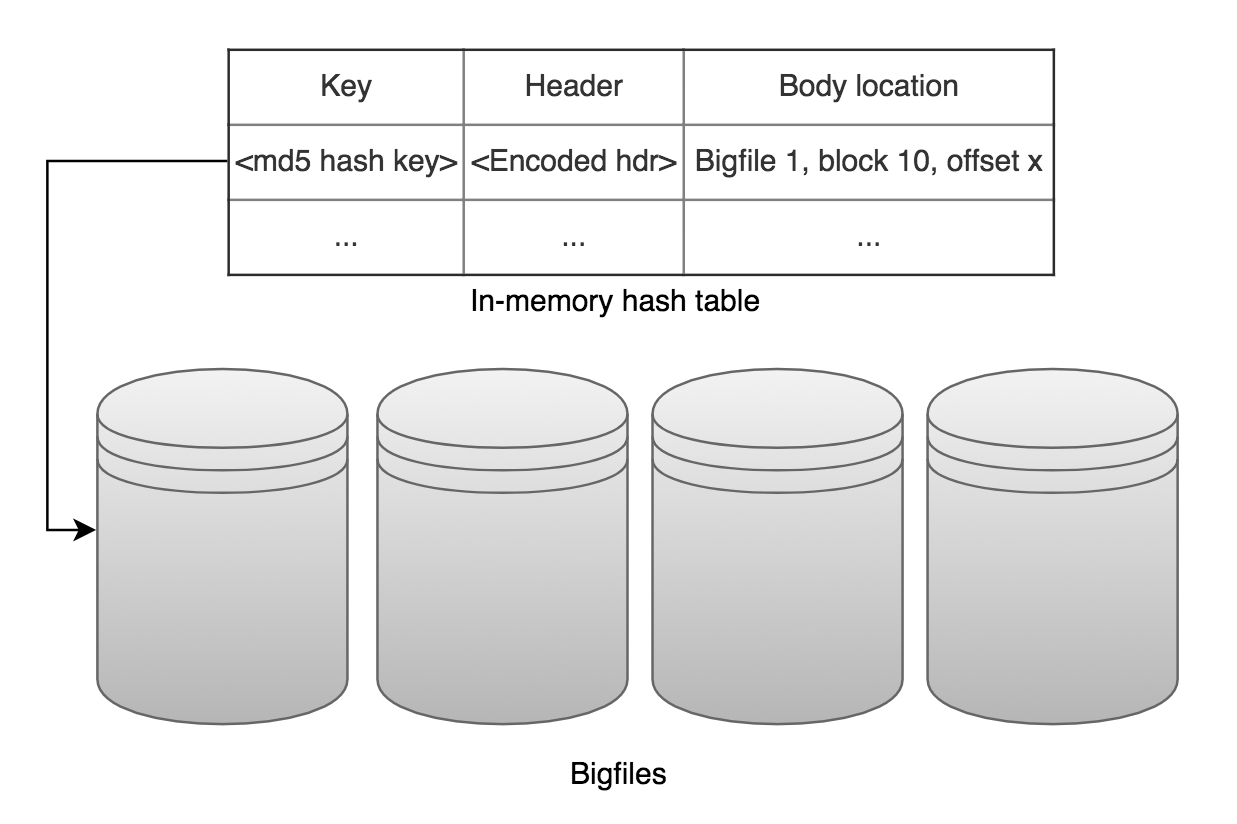
Metadata에는 URL을 기반으로 한 캐시 key와 컨텐츠가 저장되어 있는 위치(BigFile 정보 및 offset)등의 정보를 담고 있으며, 이 정보는 컨텐츠가 저장되는 BigFile과는 별개로 SQLite DB에 저장합니다.
디스크와 메모리의 효율적인 사용을 위해 Wcache는 HTTP 헤더와 일부 metadata 정보를 메모리상에 구성해둔 LRU hash table에 캐싱합니다. 메모리에 캐싱되어 있는 컨텐츠에 대해서는 DB 접근 없이 바로 응답이 가능하며, 캐싱되어 있지 않은 컨텐츠에 접근할 때는 DB에서 컨텐츠가 저장되어 있는 BigFile 정보를 읽어 컨텐츠에 대한 정보를 읽어오게 됩니다.
Wcache의 분산 구성
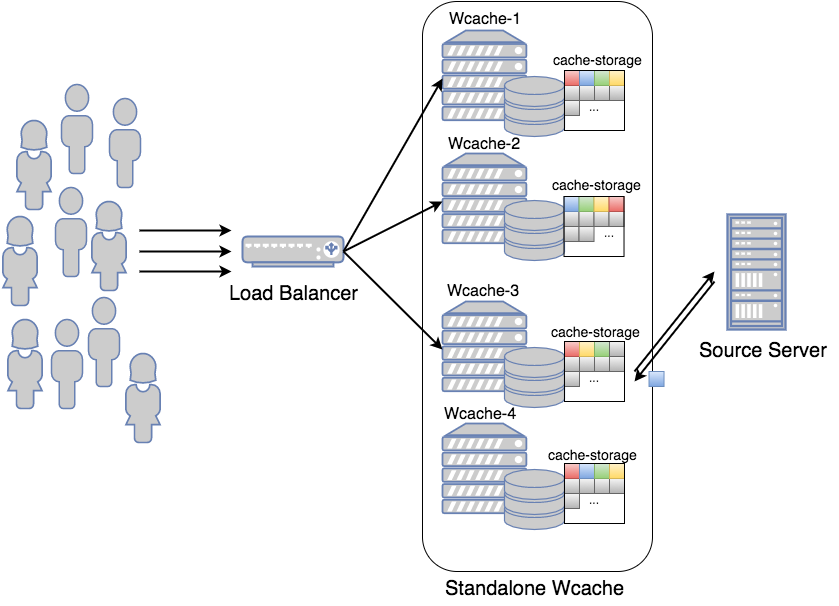
초기 Wcache는 위 그림처럼 load balancer (LB) 밑에 여러 개의 Wcache 노드를 병렬로 구성하였습니다. 트래픽 대응을 위해서는 괜찮은 구조였지만, LB가 사용자 요청을 단순히 round robin 방식으로 분산하고 있어 모든 Wcache에 중복된 컨텐츠들이 캐싱되어 이 구조로는 높은 캐시 hit율을 얻기 힘들었습니다.
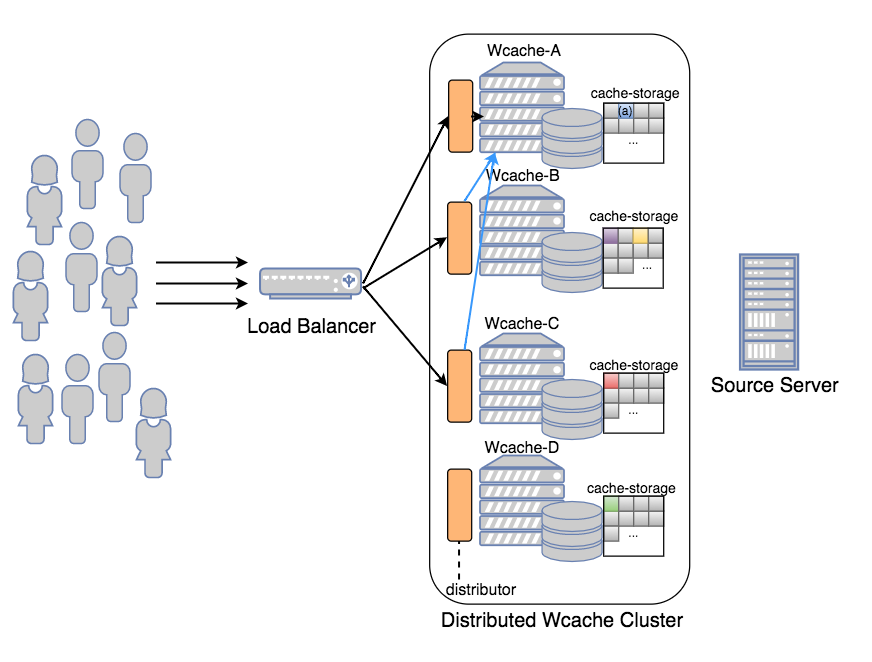
이를 해결하기 위해 Wcache는 분산 구조를 지원하였습니다. 위 그림처럼 여러 대의 Wcache 노드로 구성된 클러스터를 구성하여 consistent hashing 기법을 이용해 컨텐츠를 고르게 분포시키고, 클라이언트 요청이 들어왔을 때 알맞은 노드에 요청을 라우팅 해주도록 설계하였습니다. 이 방법은 각 Wcache가 고유한 컨텐츠를 저장함으로써 캐시 효율을 증가시킬 수는 있었습니다. 그러나 특정 컨텐츠가 인기가 많은 hot item이 되는 경우, (예: 위 그림의 Wcache-A에 존재하는 (a)컨텐츠) 수많은 요청이 하나의 Wcache로 몰리는 현상이 일어나게 되고, 결국 트래픽을 감당할 수 없게 됩니다.
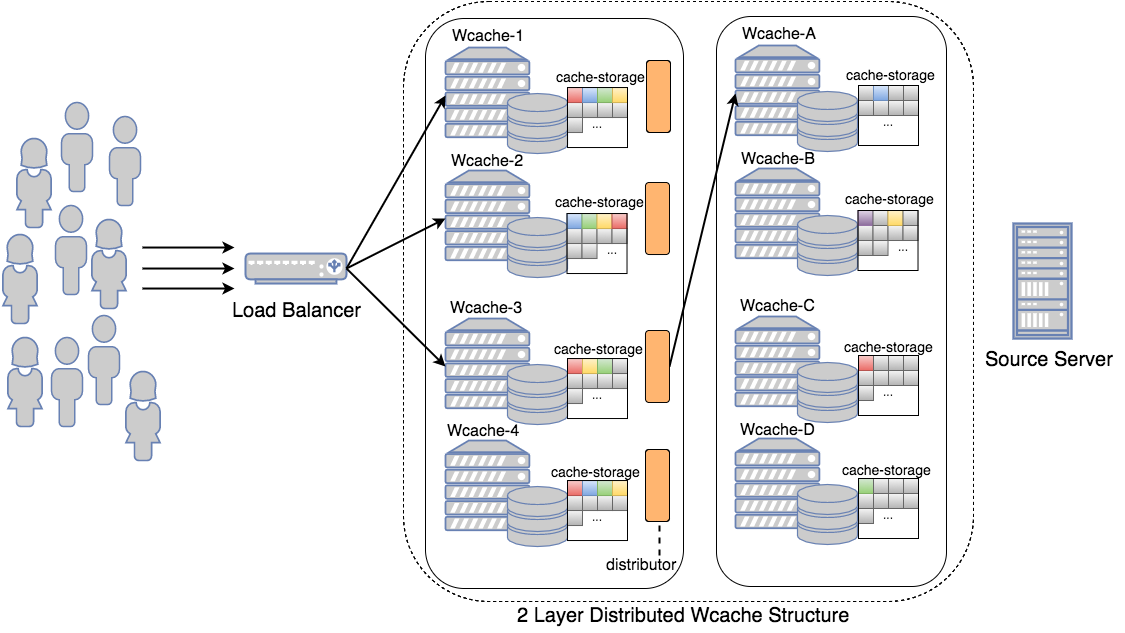
이러한 문제를 해결하기 위해, 저희는 해당 클러스터 구조를 조금 더 발전시키기로 하였습니다. 위 그림처럼 Wcache를 두 개의 layer로 나눈 후, 1차 layer에 해당하는 Wcache들이 자신만의 분산 클러스터를 2차 layer로 가지도록 구성을 합니다. 이렇게 구성하면 1차 layer에서는 트래픽을 받고, 캐시 miss가 발생했을 경우 2차 layer 중 적절한 Wcache 노드에 요청합니다. 위 구조의 효과를 배가시키기 위해 1차 layer에 I/O 속도가 빠른 SSD를 탑재한 장비를, 2차 layer에는 상대적으로 속도는 느리지만 큰 저장공간을 가진 HDD 장비를 탑재하여 빠른 응답속도와 높은 캐시 hit율, 두 마리 토끼를 전부 잡을 수 있었습니다. 특히 소수의 유명한 컨텐츠가 매우 많이 요청되고, 나머지 컨텐츠의 사용 빈도가 기하급수적으로 낮아지는 long tail2 분포를 나타내는 서비스에 대해 높은 캐시 효율과 성능을 보여 주었습니다.
결론
이렇게 구성한 Wcache는 현재 카카오 서비스에서 수십만 TPS 상당의 트래픽을 95% 이상의 높은 캐시 hit율을 가지며 안정적으로 처리하고 있습니다. 다음 포스트에서는 Wcache에 잠재되어 있는 문제점이 무엇이 있었는지, 또 어떤 방법으로 해결하였는지에 대해 알아보도록 하겠습니다.