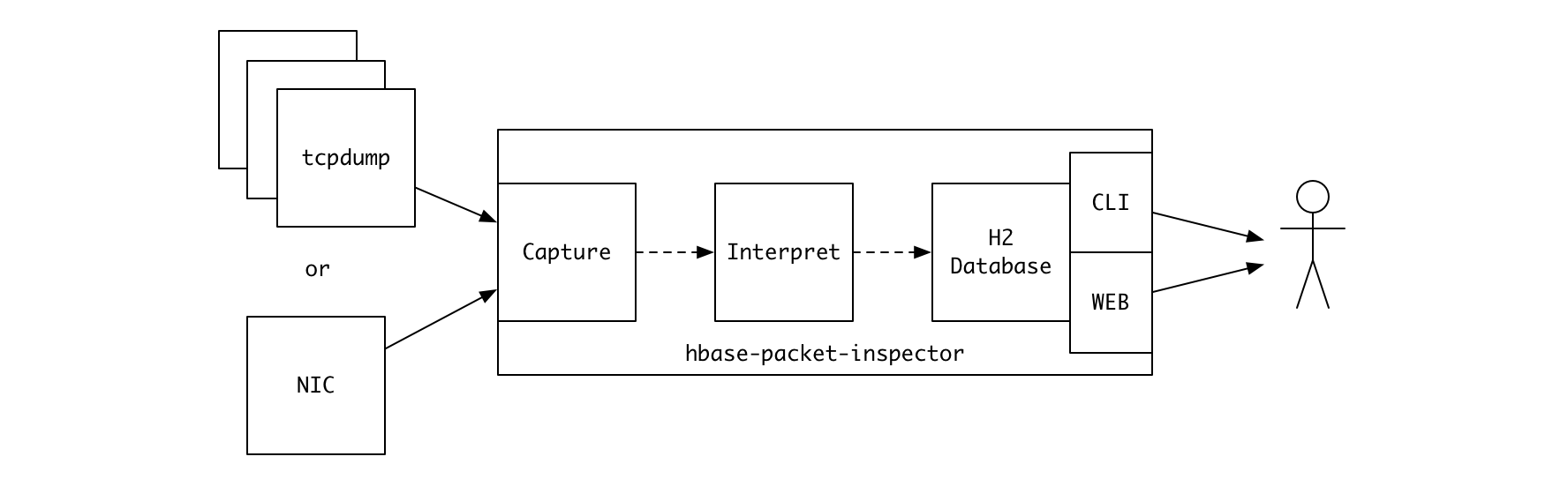
hbase-packet-inspector
이번에 카카오에서 오픈소스로 공개한 hbase-packet-inspector (이하 HPI) 는 HBase 리젼서버의 네트워크 패킷을 분석해 요청과 응답 정보를 추출하는 툴입니다. 기존의 모니터링 툴을 통해서는 알 수 없었던 보다 상세한 정보들을 확인할 수 있습니다.
먼저 왜 이런 툴이 필요했는지 이야기해봐야 할 것 같습니다.
배경/동기
카카오와 다음의 많은 서비스들은 HBase 를 중요한 데이터 저장소로 사용하고 있습니다. 서비스 간의 간섭을 피하기 위해 개별 서비스는 각각 독립적인 HBase 클러스터를 사용하는 것이 원칙이며, 그러다 보니 실제 운영 중인 HBase 클러스터는 수십 개에 이릅니다. 각 클러스터의 데이터 스키마와 액세스 패턴, 워크로드는 모두 상이하지요.
그리고 이 모든 클러스터를 5명의 인원이 시간을 나누어 운영하고 있습니다. 때문에 각 클러스터의 서비스적 특성을 모두 세밀하게 파악하고 있지 못한 것이 현실입니다. 물론 최초 클러스터 투입 시점에 전반적인 리뷰 프로세스를 거치지만 시간이 지나며 초기와는 다른 양상으로 흘러가기도 하니까요.
이러한 상황에서 서비스 장애는 발생하고, 우리는 최대한 빨리 이에 대응해야 합니다. 긴급한 서비스 장애 상황에서 빠르게 문제 원인을 파악할 수 있는 방법들이 필요합니다.
일반적인 경우
많은 경우 기본적인 모니터링만으로도 문제 파악이 가능합니다. 각 서버의 시스템 리소스 사용량이나 HBase 가 제공하는 서버 별, 리젼 별 메트릭을 확인하면 대부분의 경우는 어떠한 부분이 문제가 되고 있는지 바로 알 수 있고, 그에 대한 대응 프로세스는 이미 마련되어 있죠.
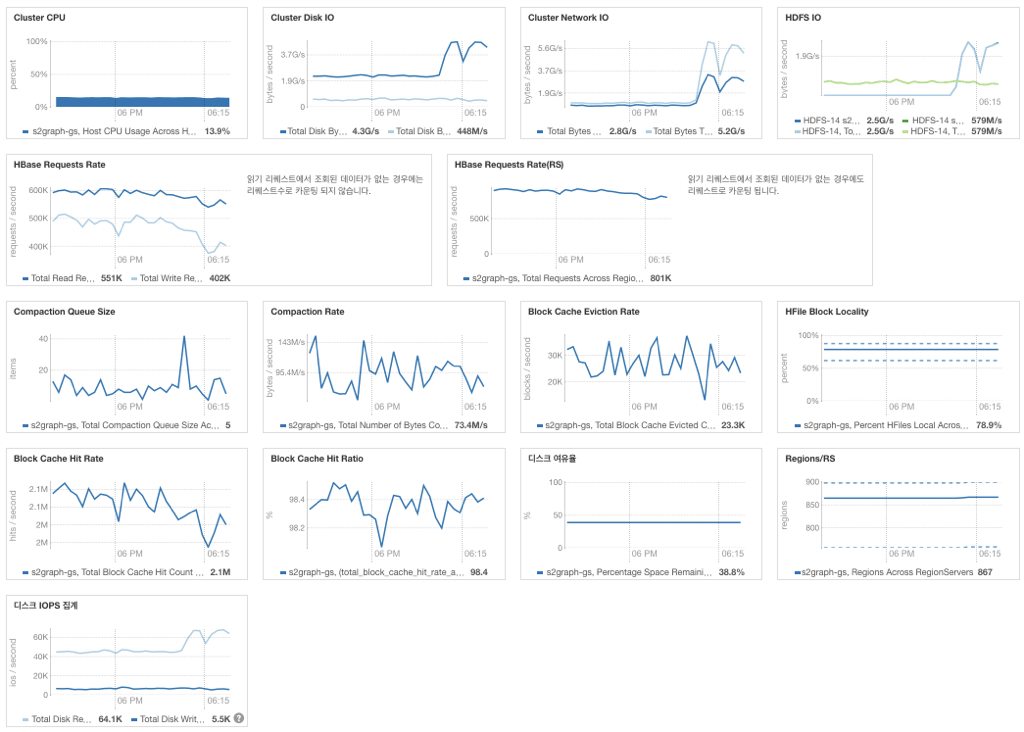
예외적인 경우
하지만 예측 범위를 벗어난 예외적인 경우들이 문제입니다. 평상시와 다른 비정상적 클라이언트 동작, 비정상적인 액세스 패턴, 또는 비정상적 데이터로 인한 문제가 발생할 경우 서버 단위의, 혹은 리젼 단위의 coarse-grained 지표만 가지고는 빠른 문제 파악이 어렵습니다.
정확히 어떤 데이터가, 어떤 클라이언트의 어떤 오퍼레이션에 의해, 어떤 빈도로 조회되고 갱신되고 있는지 정확히 진단할 수 있는 방법이 필요했습니다. 1
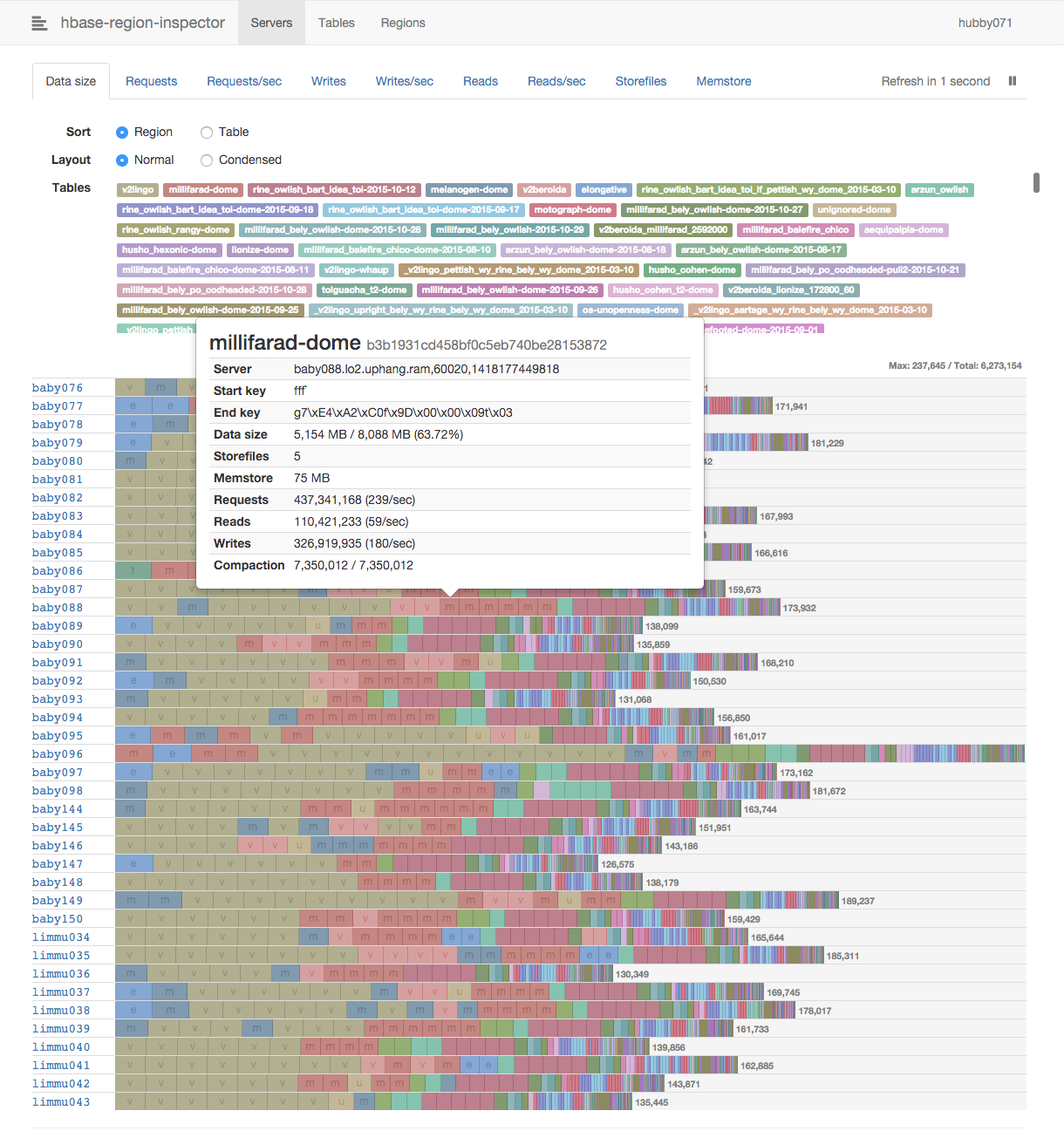
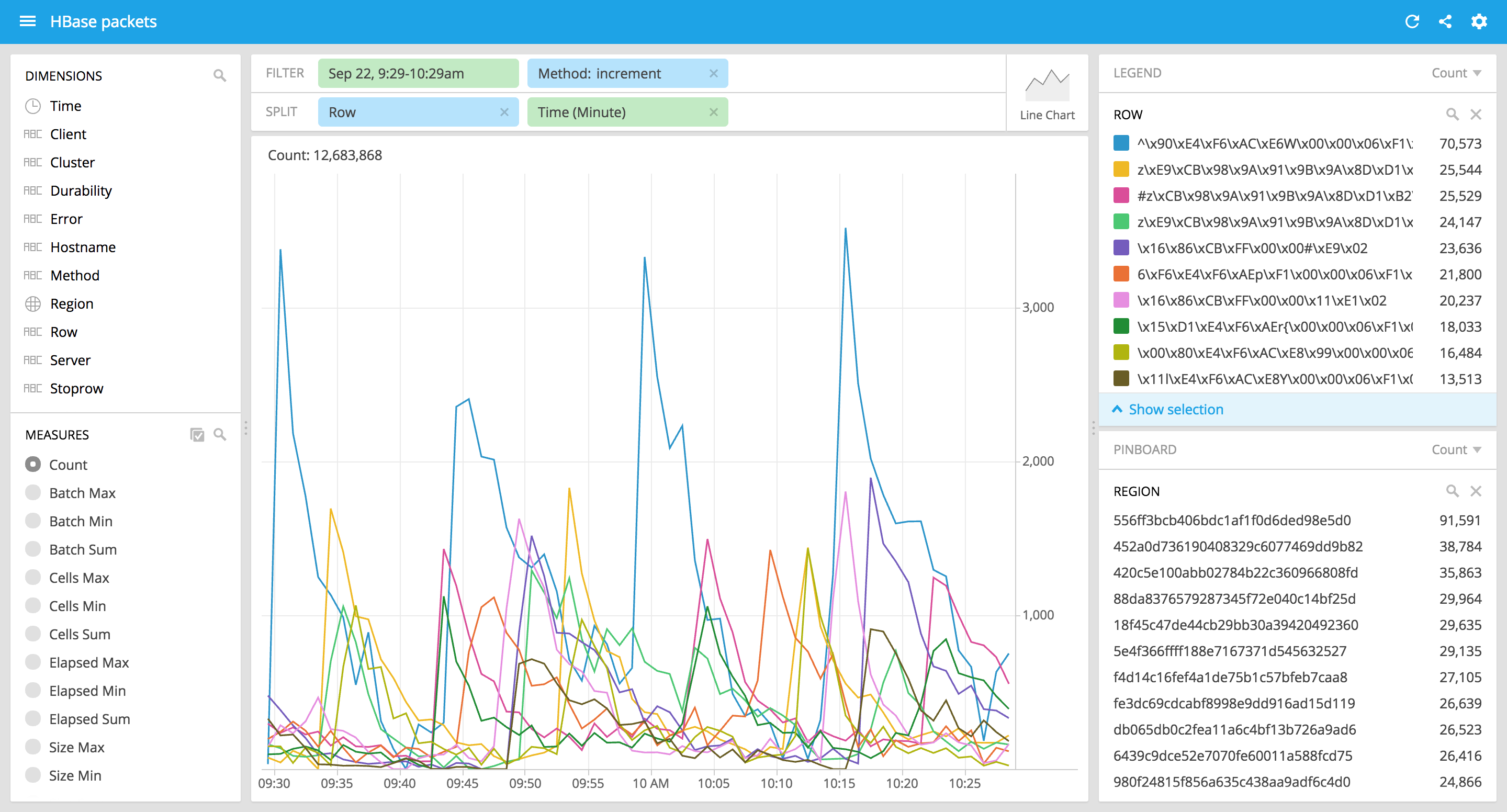
구체적으로 예를 들어 어떤 로우키 (row key) 2 로 액세스가 집중되고 있는지 파악이 필요한 경우가 있었습니다. 특정 레코드로 쓰기가 집중될 경우 경합이 발생하게 되고 시스템 리소스에 여유가 있음에도 불구하고 애플리케이션 성능은 낮게 나타날 수 있습니다. 일반적인 모니터링 지표 (CPU 사용량, HBase 리퀘스트 처리량 등) 로는 감지하기 어려운 상황입니다. 이런 상황을 파악하고, 문제가 되는 레코드를 정확히 확인할 수 있다면 효과적인 대응이 가능하겠죠.
기존의 모니터링 도구로는 대응이 불가능한 부분이었고, 담당 서비스 팀에서도 정확한 추적이 어려운 상황이었습니다. 마지막 수단으로 ngrep 을 이용해 네트워크 패킷의 바이트 스트림을 눈으로 따라가 보았습니다.
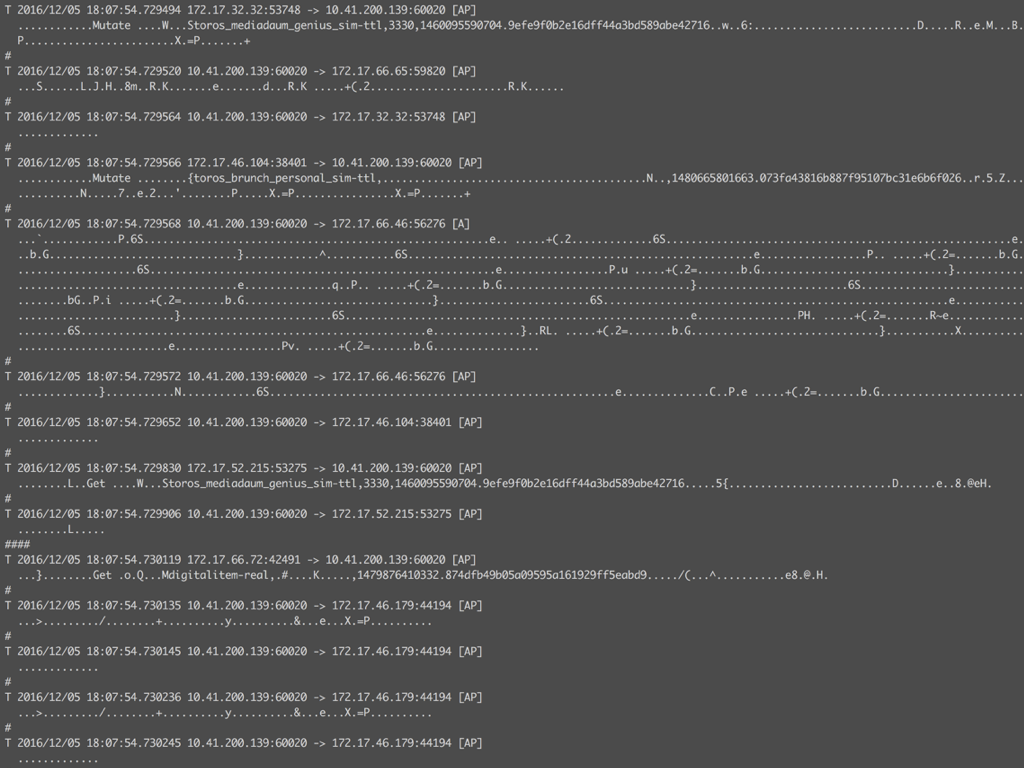
테이블명, 오퍼레이션 타입, 접근하는 로우키 정보들을 어렴풋이 확인할 수 있습니다. 여기서 많이, 자주 보이는 로우키들을 기억해서 서비스 담당팀에 전달하는 것이 당시 우리가 할 수 있는 최선이었죠. 프로세스는 비효율적이고 부정확했습니다.
흔히 발생하는 상황은 아니었지만, 그 후로도 이러한 경우들이 여러 번 반복되었고, 보다 체계적으로 대응해야 할 필요성을 느끼게 됩니다.
“이럴 거면 제대로 까 봅시다.”
HBase 프로토콜을 이해하는 패킷 분석 도구를 만들기로 했습니다. 명칭은 이미 오픈소스로 공개한 hbase-region-inspector 와 유사하게 hbase-packet-inspector 로 정했습니다.
HBase RPC
개발을 위해선 HBase RPC 에 대한 이해가 필요합니다. 다행히 HBase 의 RPC
프로토콜은 단순한 편으로 문서화가 잘되어 있고, Protocol Buffer
기반이므로 관련 .proto 파일들을 들여다보면 메시지 구조를 모두
알 수 있습니다. 3
HBase 의 RPC 는 간단하게 다음 그림으로 요약할 수 있습니다.
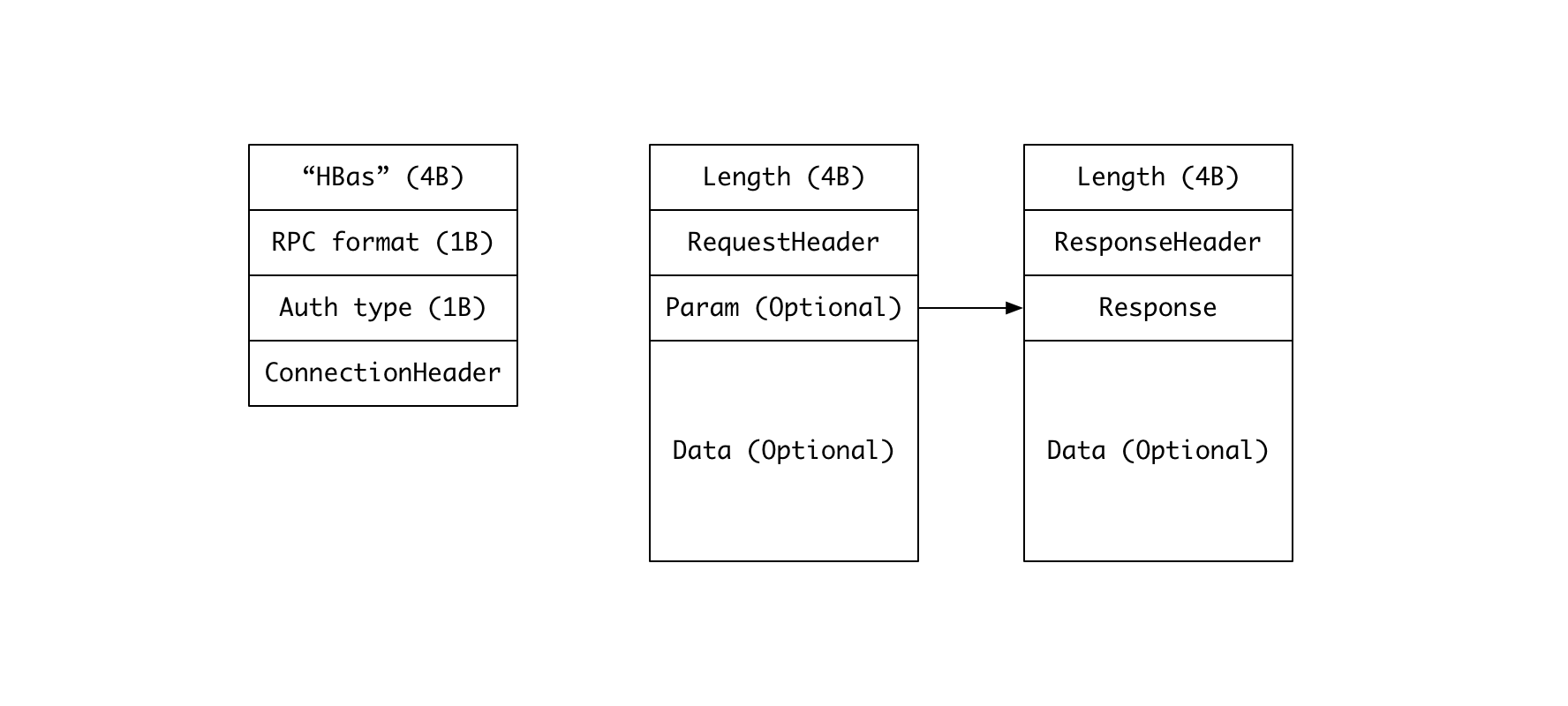
- 리젼서버와 클라이언트가 주고받는 모든 메시지는 메시지의 길이를 나타내는 4-byte integer 로 시작합니다.
- 한 가지 예외는 최초 커넥션 생성 시 클라이언트가 전송하는 메시지로, 길이 정보
대신
HBas라는 특수 문자열을 전송합니다. 해당 메시지는 우리가 원하는 정보를 추출하는 데 있어 중요하지 않으므로 무시합니다. - 요청 (request) 의 경우 길이를 나타내는 4-byte integer 뒤에 RequestHeader 가 따르고, 요청의 상세 정보를 담은 파라미터가 이어집니다. 쓰기 오퍼레이션의 경우 추가적으로 데이터가 붙게 됩니다.
- 응답 (response) 도 유사한 형태인데 RequestHeader 대신 ResponseHeader 가 붙습니다.
RequestHeader 와 ResponseHeader 의 Protocol Buffer message 정의는 다음과 같습니다.
message RequestHeader {
optional uint32 call_id = 1;
optional RPCTInfo trace_info = 2;
optional string method_name = 3;
optional bool request_param = 4;
optional CellBlockMeta cell_block_meta = 5;
optional uint32 priority = 6;
}
message ResponseHeader {
optional uint32 call_id = 1;
optional ExceptionResponse exception = 2;
optional CellBlockMeta cell_block_meta = 3;
}
요청의 경우 RequestHeader 를 보면 어떤 타입의 요청인지 (method_name), 어떤
파라미터로 요청되었는지 모두 알 수 있지만, 응답의 경우 그러한 정보가
직접적으로 주어져 있지 않아 매칭 되는 요청을 call_id 기준으로 찾아봐야
합니다. 따라서 HPI 는 패킷 스트림을 분석하면서 call_id 에 해당하는 원래의
요청을 내부 상태로 기억하고 관리합니다.
커넥션의 단절, 또는 pcap 의 패킷 드랍으로 인해, 요청에 대한 응답을 HPI 가 보지 못하는 경우들이 발생할 수 있습니다. 이러한 경우들이 장기간 누적되면 내부 상태 관리에 필요한 메모리 사이즈가 지속적으로 증가하므로 이를 시간 기준, 사용 메모리 기준으로 정리하는 로직도 구현해야 합니다.
RequestHeader 의 method_name 에 따라 해당 요청 타입에 맞는 메시지가
파라미터로 따라오게 되는데요, 간단한 예로 Get 요청의 경우 다음과 같은 메시지를
사용합니다.
message GetRequest {
required RegionSpecifier region = 1;
required Get get = 2;
}
message RegionSpecifier {
required RegionSpecifierType type = 1;
required bytes value = 2;
// 후략
}
message Get {
required bytes row = 1;
repeated Column column = 2;
repeated NameBytesPair attribute = 3;
optional Filter filter = 4;
optional TimeRange time_range = 5;
optional uint32 max_versions = 6 [default = 1];
optional bool cache_blocks = 7 [default = true];
// 후략
}
우리가 원하는 정보 – 어떤 리젼을 향하는 요청인지, 어떤 로우키에 대한 요청인지 등 – 를 모두 추출할 수 있죠.
Scan 의 경우는 조금 복잡한데요, 하나의 scan 작업은 최초의 open scanner, 1번
이상의 next rows, 최종 close scanner 의 세 번 이상의 RPC 로 구성되고 4,
이들은 개별적인 RPC 로서 서로 다른 call_id 를 갖습니다. 이들을 이어주는 것은
open scanner 응답에 포함된 scanner_id 로 이를 내부 상태로 관리하고 연관된
RPC 를 묶어주는 작업이 필요합니다.
추가적으로 패킷 분석 시 신경 써야 했던 부분들은 다음과 같습니다.
- 메시지 크기가 MTU 1500 바이트를 초과하는 경우 하나의 메시지가 여러 패킷에 걸쳐 전송됩니다. 이를 합쳐 원래의 온전한 메시지를 복원해야 합니다.
- 반대로 하나의 패킷에 여러 개의 메시지가 붙어 있는 경우도 있습니다. 이런 경우는 Asynchbase 클라이언트 사용 시 자주 관찰되는데요. 한 패킷에 포함된 여러 메시지 중 마지막 메시지의 경우 온전한 형태가 아니라 다음 패킷에 걸쳐 있을 수도 있으므로 이에 대한 처리도 해주어야 했습니다.
- 패킷 스트림이 stateful 하므로 병렬 처리 시에는 클라이언트의 IP 와 port 기준으로 multiplexing 해야 합니다. 현재 HPI 는 패킷을 캡처하는 thread 와 이를 HBase 요청과 응답으로 해석하는 thread, 두 개의 thread 만 사용하고 있으므로 이러한 구현은 하지 않고 있습니다. 병렬도를 늘린다면 HPI 의 처리 성능을 높여 더 정확한 통계를 얻을 수 있겠지만, 더 많은 CPU 를 사용하게 되므로 HPI 를 리젼서버 상에서 실행하는 경우에는 원하는 동작이 아닐 수 있겠지요.
SQL 기반의 분석 도구 제공
원하는 정보를 추출했다면, 이를 어떻게 보여줄 것인가의 고민이 이어집니다. 최초에는 hbase-region-inspector 와 유사하게 웹을 통한 시각화를 고려했지만, 요구 사항을 나열해보니 난감했어요.
- 가장 많이 액세스가 이루어지는 로우키의 목록은?
- 특정 리젼에서 increment 오퍼레이션이 가장 많이 일어나는 로우키의 목록은?
- 20KB 이상의 check and put 요청을 보내는 클라이언트들이 접근하는 리젼 별 평균 응답 시간은?
생각해보면 끝이 없습니다. 이토록 다양한 형태의 요구를 모두 수용할 수 있을 만큼 강력하고 유연한 사용자 인터페이스는 무엇이 있을까, 우리의 오랜 친구 SQL 이 떠올랐습니다. 위의 요구 사항은 다음과 같이 표현해볼 수 있겠네요.
-- 가장 많이 액세스가 이루어지는 로우키의 목록은?
select table, row, count(*)
from requests
where row is not null
group by table, row
order by 3 desc limit 30;
-- 특정 리젼에서 increment 오퍼레이션이 가장 많이 일어나는 로우키의 목록은?
select table, row, count(*)
from requests
where method = 'increment' and region = 'a073a39457e367c197fb0ae5af4d5656'
group by table, row
order by 3 desc limit 30;
-- 20KB 이상의 check and put 요청을 보내는 클라이언트들이 접근하는 리젼별 평균 응답 시간은?
select region, avg(elapsed)
from responses
where client in (
select distinct client from requests
where method = 'check-and-put' and size > 20 * 1024
)
group by region
order by 2 desc limit 30;
미려한 시각화는 없지만 유연하고 강력합니다. SQL 인터페이스를 제공하기로 결정합니다.
빠르고 간단하게 실행할 수 있는 툴을 만드는 것이 목표였기 때문에 외부 데이터베이스 연동을 고려하지는 않았고 5, H2 데이터베이스를 내장해 메모리 데이터베이스에 적재하기로 했습니다.
H2 가 제공하는 큰 장점은 커맨드 라인과 웹 기반의 SQL 인터페이스를 내장하고 있다는 점이었는데요, 덕분에 사용자 인터페이스를 개발하는데 시간을 전혀 들이지 않고 빠른 프로토타이핑이 가능했습니다.
실행 화면
HPI 를 실행하면 지정한 네트워크 인터페이스에 대한 패킷 캡처를 시작합니다.
분석한 내용을 메모리 데이터베이스에 적재하므로, 마냥 계속 유지할 수는 없고
heap 영역 부족이 발생하기 전에 중단해야 합니다. 지정된 시간 동안
(--duration) 혹은 지정된 개수의 패킷을 처리할 때까지 (--count) 유지하도록
할 수도 있고, 사용자의 키 입력 시점까지 유지할 수도 있습니다.
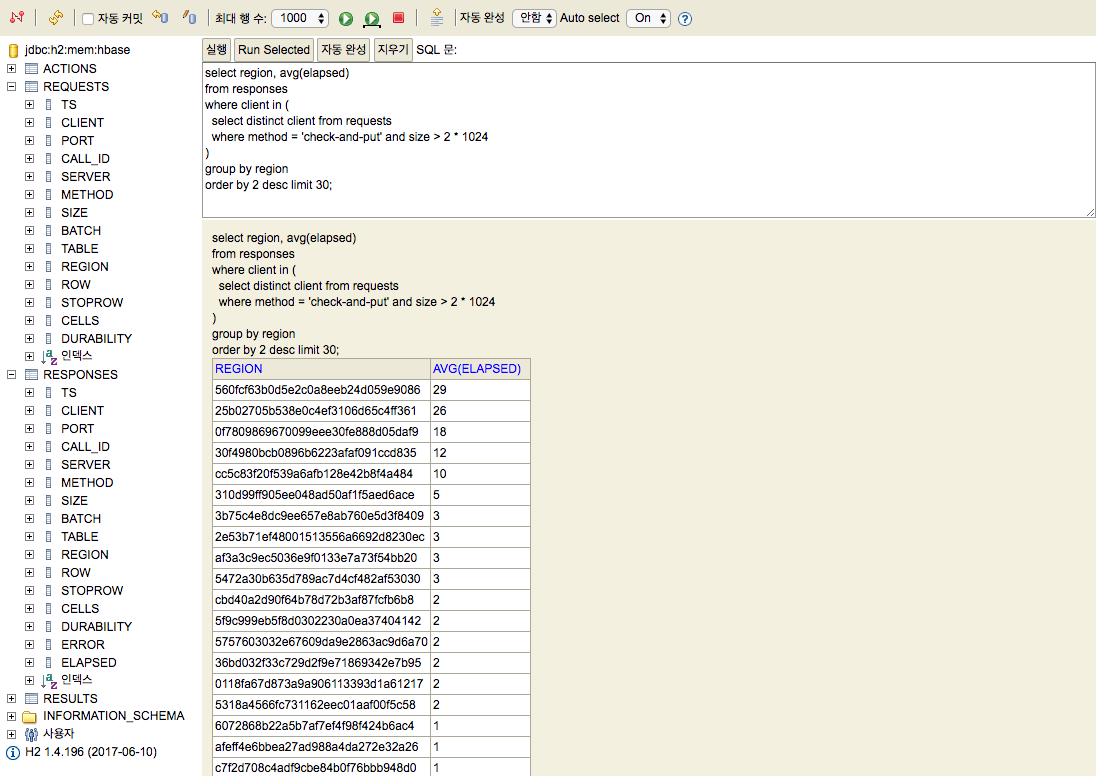
아래 보시는 내용은 50만 개의 패킷을 처리한 시점에서 처리를 중단한 후, H2 가 제공하는 SQL 인터페이스로 데이터를 조회해보는 모습입니다.
...
2017-09-21 16:35:04,535 INFO : Processed 480000 packets (received: 492384, dropped: 2395)
2017-09-21 16:35:05,163 INFO : Processed 490000 packets (received: 502395, dropped: 2395)
2017-09-21 16:35:05,966 INFO : Processed 500000 packets (received: 513683, dropped: 2395)
2017-09-21 16:35:06,513 INFO : Closing the handle
2017-09-21 16:35:06,514 INFO : 520487 packets received, 2395 dropped
2017-09-21 16:35:06,541 INFO : Closed.
2017-09-21 16:35:06,987 INFO : Started web server: http://10.41.200.107:44764/frame.jsp?jsessionid=4af2da9103cf1ab23aeb2a311ea8c32f
Welcome to H2 Shell 1.4.196 (2017-06-10)
Exit with Ctrl+C
Commands are case insensitive; SQL statements end with ';'
help or ? Display this help
list Toggle result list / stack trace mode
maxwidth Set maximum column width (default is 100)
autocommit Enable or disable autocommit
history Show the last 20 statements
quit or exit Close the connection and exit
sql> select region, avg(elapsed)
...> from responses
...> where client in (
...> select distinct client from requests
...> where method = 'check-and-put' and size > 2 * 1024
...> )
...> group by region
...> order by 2 desc limit 10;
REGION | AVG(ELAPSED)
560fcf63b0d5e2c0a8eeb24d059e9086 | 29
25b02705b538e0c4ef3106d65c4ff361 | 26
0f7809869670099eee30fe888d05daf9 | 18
30f4980bcb0896b6223afaf091ccd835 | 12
cc5c83f20f539a6afb128e42b8f4a484 | 10
310d99ff905ee048ad50af1f5aed6ace | 5
3b75c4e8dc9ee657e8ab760e5d3f8409 | 3
2e53b71ef48001513556a6692d8230ec | 3
af3a3c9ec5036e9f0133e7a73f54bb20 | 3
5472a30b635d789ac7d4cf482af53030 | 3
(10 rows, 245 ms)
sql>
그리고 앞서 언급한 것처럼 웹 기반의 SQL 인터페이스가 공짜로 따라오지요. 화려하진 않지만 원하는 기능은 모두 수행할 수 있습니다.
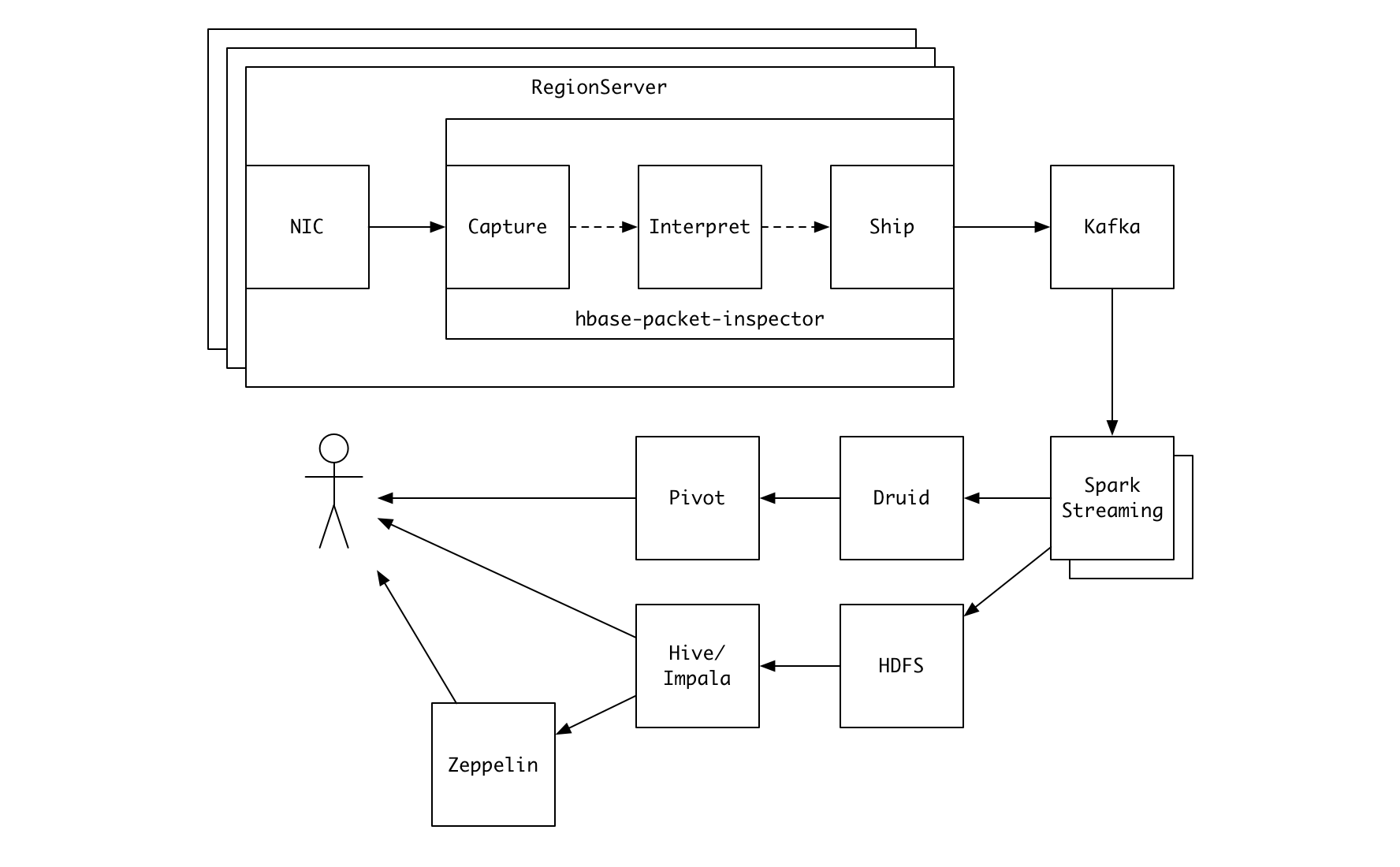
Apache Kafka 연동 기능의 추가
이 정도로도 그럭저럭 쓸만한 상태가 되었고, 한동안 잘 활용했지만 한계는 뚜렷했습니다.
- 메모리 데이터베이스이므로 수집할 수 있는 데이터의 크기가 제한적이다. 장시간에 걸친 분석이 불가능하다.
- 수집이 끝난 후에는 데이터베이스 내용이 더 이상 갱신되지 않으므로 워크로드의 실시간 변화를 관찰할 수 없다.
- HPI 가 실행 중인 리젼서버, 혹은 애플리케이션 서버의 정보만 수집되므로 클러스터 전반의 종합적인 워크로드 파악이 불가능하다.
- 문제 분석의 자동화가 어렵다.
다수의 서버에서 HPI 를 중단 없이 장기간 실행하고 수집된 결과를 취합해 실시간으로 분석해보고 싶었습니다. 이에 Apache Kafka 로의 전송 기능을 도입하게 되었습니다.
Kafka 로 전송할 경우, 복수개의 consumer 를 이용해 다양한 방식으로 데이터를 가공해 유연하게 활용할 수 있다는 장점이 있습니다. 카카오에서 Kafka 가 데이터 연동 시 “사실상 표준” 도구로서 활용되고 있다는 점도 선택에 영향을 주었죠.
java -jar hbase-packet-inspector.jar \
--kafka "bootstrap1:9092,bootstrap2:9092//hbase-responses"
패킷 캡처 방식은 서버의 최대 성능에 영향을 주는 것으로 알려져 있고, HPI 도 예외는 아닙니다. 리젼서버의 부하가 높은 상황이라면 HPI 를 리젼서버가 아닌 애플리케이션 서버 쪽에서 실행하는 것이 안전하겠죠 6. HPI 는 포트 번호를 기준으로 서버 여부를 판단하므로 반드시 리젼서버 상에서 실행할 필요가 없습니다. 다음과 같은 형태가 됩니다.
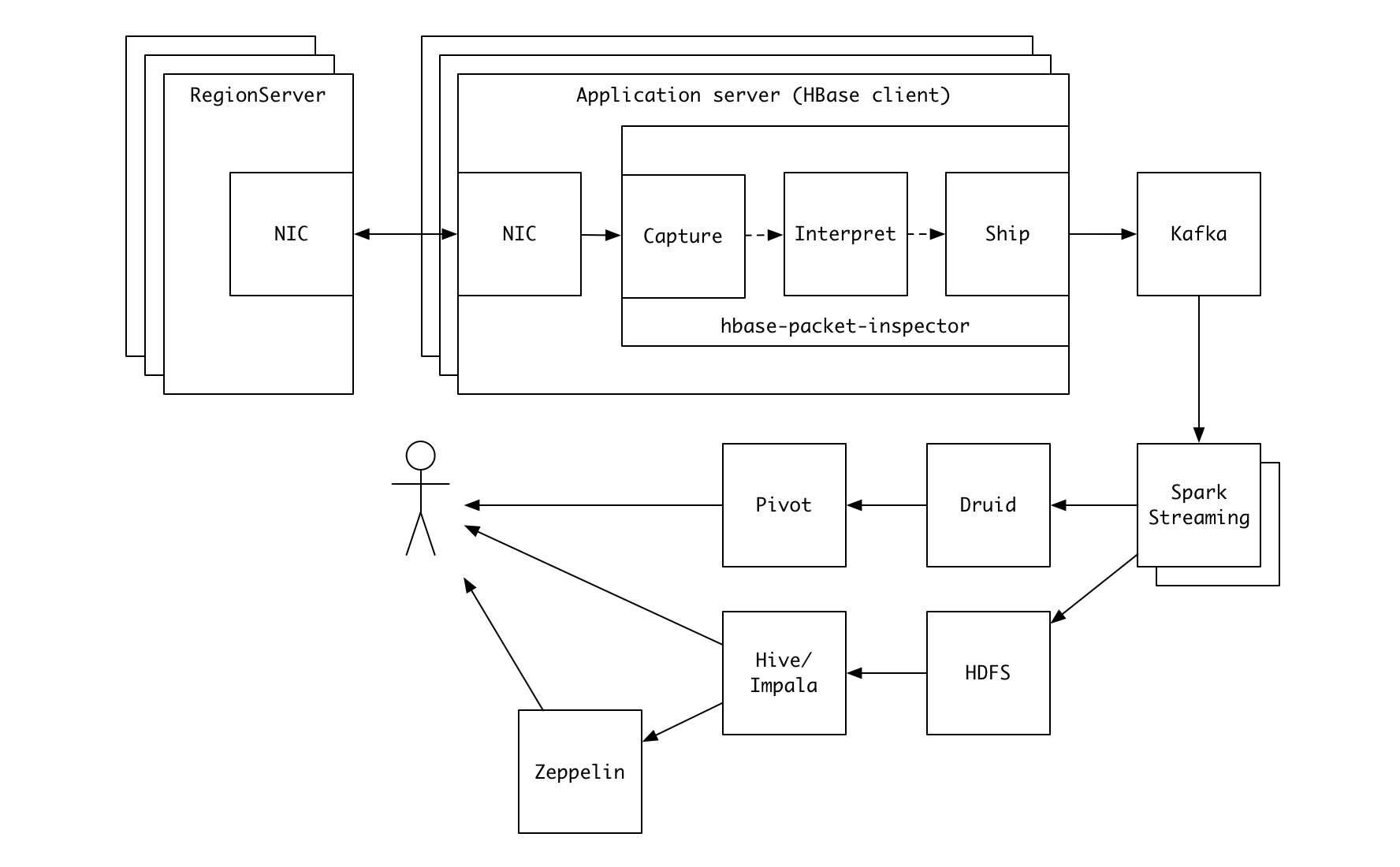
Kafka 로 전송된 데이터는 위의 그림에 표현한 것처럼 다양한 방식으로 활용이 가능한데요, 카카오에서는 Spark streaming 으로 데이터를 가공해 OLAP 엔진인 Druid 으로 실시간 전송하고 Pivot 으로 시각화하여 확인하고 있습니다.
여기서 한걸음 더 나아가 Druid API 를 이용해 주기적으로 클러스터 핫스팟 분석을 수행하고, 이에 따른 적절한 대응을 자동으로 수행하는 고도화 작업을 진행하고 있습니다.
마치며
아직 부족한 점들이 있지만 HPI 는 HBase 클러스터의 모니터링과 운영 프로세스를 개선하는데 적지 않은 도움을 주고 있습니다. 오픈소스 공개 이후에도 지속적으로 개선해 나갈 예정이며 비슷한 고민(과 고생)을 하신 분들께 도움이 되길 바랍니다.
-
원칙적으로 이러한 액세스 패턴에 대한 지표는 개별 서비스 담당팀에 의해 추적/모니터링이 되는 것이 맞겠습니다. 하지만 여러 현실적인 이유로 그에 대한 대비가 충분히 되지 않은 경우들이 있을 수 있고, 서비스 장애 상황에 급하게 이에 대한 추가 개발/배포를 요구하는 것은 어렵죠. ↩
-
HBase 데이터 테이블의 primary key ↩
-
HPI 는 JVM 에서 동작하는 Clojure 로 개발했으므로 proto 파일에 대한 별도의 전처리 없이 HBase 서버와 클라이언트가 사용하는 Java API 를 그대로 사용할 수 있습니다. ↩
-
Small scan 인 경우는 예외로 한 번의 RPC 로 이루어집니다. HPI 는 small scan 여부를 구분합니다. ↩
-
JDBC 드라이버, 유저명, 패스워드, 접속 권한, 테이블 생성 권한 … ↩
-
단순히 tcpdump 를 실행하는 것만으로도 서버의 최대 성능이 10 ~ 15% 가량 저하되는 것을 확인할 수 있습니다 (이는 최대 성능의 관점이며 서버의 처리량이 높지 않은 상태라면 그 정도의 차이가 관찰되지는 않습니다). HPI 의 경우도 유사하나 HPI 는 단순한 tcpdump 보다 더 많은 CPU 자원을 사용하므로 추가적인 주의가 필요합니다. 카카오에서는 서비스의 안정적 운영을 위해 시스템 리소스에 어느 정도 여유가 있는 수준으로 클러스터의 규모를 산정하기 때문에 HPI 를 추가적으로 실행하는데 큰 무리가 없습니다. ↩