“카카오의 오픈소스를 소개합니다” 일곱 번째는 jon.kwon과 동료들이 개발한 CMUX입니다.
CMUX는 Cloudera Manager 기반의 하둡 클러스터를 관리하는데 필요한 대화형 커맨드라인 인터페이스 도구들을 제공합니다.
CMUX의 아이디어를 참고해 보세요. 여러분의 커맨드라인에 날개를 달 수 있을 것입니다.
카카오의 하둡 엔지니어링 파트에서는 CMUX를 이렇게 사용합니다.
수천 대의 하둡 클러스터의 정보를 빠르게 검색하여 필요한 정보를 조회하기도 하고,

특정 조건으로 검색한 노드에 SSH 로그인하여 병렬 작업을 하거나,

특정 조건으로 검색한 관리자 웹페이지를 열어보기도 합니다.


특정 조건으로 검색한 노드에만 명령어를 실행할 수도 있습니다.

필요하면 외부 툴을 실행할 수도 있죠.

조금만 여유가 있다면 Rolling restart role처럼 아주 복잡한 유지 보수 작업이나 배치 작업을 만들어서 사용할 수도 있습니다.
지금부터 이런 것들을 가능하게 한 CMUX의 아이디어를 소개해 드리겠습니다.
CMUX의 작업 흐름
CMUX는 크게 4단계의 작업 흐름으로 구성된 명령어 집합입니다.

입력 단계
입력 소스는 파일, 파이프라인, API 등 여러분이 상상할 수 있는 다양한 형태가 될 수 있습니다. CMUX에서는 Cloudera Manager의 REST API와 카카오의 인프라 자원을 조회하는 API를 주로 사용합니다.
검색 / 필터 단계
CMUX의 꽃에 해당되는 부분입니다. 빔(Vim)신이라고 불리는 카카오의 jg.choi이 만드신 FZF라는 커맨드라인 검색 도구를 사용하여, 원하는 조건으로 입력을 검색하고 결과를 걸러냅니다.
명령어 생성 단계
걸러진 결과를 바탕으로 명령어 또는 명령어 집합을 생성합니다. CMUX는 Ruby로 작성되어 있기 때문에 당연히 Ruby 코드로 생성하겠죠.
명령어 실행 단계
생성한 명령어 또는 명령어 집합을 실행합니다. 이때 명령어 집합을 병렬로 실행할 수 있는 인터페이스가 필요할 수 있는데, CMUX는 이를 위해 TMUX를 사용합니다.
그럼, 이해를 돕기 위해 간단한 예제 코드를 통해 이 과정을 구현해 보겠습니다.
구현 예제
준비
CMUX의 아이디어를 구현하기 위해 필요한 두 가지 도구인 FZF, TMUX를 설치합니다. OS X 유저라면 homebrew로 간단하게 설치할 수 있습니다.
brew install tmux fzf
CMUX는 Ruby로 작성되어 있지만, 이 예제에서는 쉘 스크립트로 간단하게 구현해 보겠습니다. 그리고 쉘에서 JSON 포맷으로 제공되는 Cloudera Manager REST API를 편하게 활용할 수 있도록 jq를 설치하겠습니다.
brew install jq
자 이제 준비가 되었으니, 데이터 입력 부분부터 구현해 볼까요?
입력
Cloudera Manager REST API를 활용하여, Cloudera Manager에 생성되어 있는 클러스터 정보를 취득하겠습니다.
$ CM="test.kakao.cm"
$ CM_PORT="7180"
$ CM_API_VER="v14"
$ CM_USER="hadoop"
$ CM_USER_PWD="doopy"
$ RESOURCE="/clusters"
$ BASE_URL="$CM:$CM_PORT/api/$CM_API_VER"
$ URL="$BASE_URL$RESOURCE"
$ curl -f -s -u "$CM_USER":"$CM_USER_PWD" "$URL"
대략 이런 모습의 결과를 확인할 수 있을 것입니다. Cloudera Manager가 없는 환경이라고 낙담하지 않으셔도 됩니다. 다음 단계부터는 아래의 내용을 clusters.txt로 저장했다고 가정하고 진행하겠습니다.
{
"items" : [{
"name" : "cluster1",
"displayName" : "Neo",
"version" : "CDH5",
"fullVersion" : "5.3.8",
"maintenanceMode" : false,
"maintenanceOwners" : [ ],
"clusterUrl" : "https://www.kakaofriends.com/kr/products/groups/characters/8",
"hostsUrl" : "https://www.kakaofriends.com/kr/products/groups/characters/8",
"entityStatus" : "NONE"
}, {
"name" : "cluster2",
"displayName" : "Ryan",
"version" : "CDH5",
"fullVersion" : "5.11.1",
"maintenanceMode" : true,
"maintenanceOwners" : [ "CLUSTER" ],
"clusterUrl" : "https://www.kakaofriends.com/kr/products/groups/characters/23",
"hostsUrl" : "https://www.kakaofriends.com/kr/products/groups/characters/23",
"entityStatus" : "GOOD_HEALTH"
}, {
"name" : "cluster3",
"displayName" : "Apeach",
"version" : "CDH5",
"fullVersion" : "5.3.8",
"maintenanceMode" : true,
"maintenanceOwners" : [ ],
"clusterUrl" : "https://www.kakaofriends.com/kr/products/groups/characters/6",
"hostsUrl" : "https://www.kakaofriends.com/kr/products/groups/characters/6",
"entityStatus" : "GOOD_HEALTH"
} ]
}
검색/필터
호출된 결과를 jq 명령어를 이용해서 특정 필드만 가져오도록 하겠습니다.
우리는 “클러스터 이름(name)”, “클러스터 표시 명(displayName)”, “클러스터 관리자 페이지 URL(clusterUrl)”에만 관심이 있습니다.
$ cat clusters.txt \
| jq -r '.items[] | [.name, .displayName, .clusterUrl]'
잘 걸러졌습니다.
[
"cluster1",
"Neo",
"https://www.kakaofriends.com/kr/products/groups/characters/8"
]
[
"cluster2",
"Ryan",
"https://www.kakaofriends.com/kr/products/groups/characters/23"
]
[
"cluster3",
"Apeach",
"https://www.kakaofriends.com/kr/products/groups/characters/6"
]
이제, 특정 클러스터를 검색하고 필터링할 수 있도록 하겠습니다.
먼저, 위 결과를 클러스터별로 선택 가능하도록 jq의 join문으로 열을 결합합니다.
$ cat clusters.txt \
| jq -r '.items[] | [.name, .displayName, .clusterUrl] | join("\t")'
cluster1 Neo https://www.kakaofriends.com/kr/products/groups/characters/8
cluster2 Ryan https://www.kakaofriends.com/kr/products/groups/characters/23
cluster3 Apeach https://www.kakaofriends.com/kr/products/groups/characters/6
참고
CMUX에서는 결과물을 잘 정렬된 테이블 형태로 출력할 수 있도록, 이 부분을 별도의 모듈로 구현하였습니다.
내가 원하는 결과를 검색하고 선택할 수 있도록 해 볼까요?
fzf 명령어를 파이프에 연결하겠습니다.
--multi: 다중 선택--reverse: 역순 레이아웃, 기본값은 아래에서 위로 정렬합니다.
$ cat clusters.txt \
| jq -r '.items[] | [.name, .displayName, .clusterUrl] | join("\t")' \
| fzf --multi --reverse
위 스크립트를 실행하면 아래와 같이 선택 가능한 상태로 FZF가 활성화됩니다.

“Ryan”이라는 클러스터 이름을 검색하겠습니다.
“Fuzzy Finder”라는 이름에 걸맞게 아래와 같이 느슨한 검색이 가능합니다. 다양한 검색 옵션이 있으니, fzf의 man 페이지를 읽어보시기 바랍니다.

이번엔 “Neo”와 “Apeach” 클러스터를 선택하겠습니다. 기본적으로 tab 키로 선택할 수 있습니다. 전체 선택, 전체 선택 해제 등 다양한 옵션이 있으니, 마찬가지로 man 페이지를 읽어보시기 바랍니다.

최종 선택한 결과는 아래와 같이 문자열로 반환됩니다.
cluster1 Neo http://test.kakao.cm:7180/cmf/clusterRedirect/cluster
cluster3 Apeach http://test.kakao.cm:7180/cmf/clusterRedirect/cluster2
명령어 생성
결과의 마지막 열인 “Cluster URL”을 기본 브라우저로 열 수 있도록 명령어를 만들겠습니다. OS X 환경이라는 가정하에 open 명령어를 사용합니다.
$ cat clusters.txt \
| jq -r '.items[] | [.name, .displayName, .clusterUrl] | join("\t")' \
| fzf --multi --reverse \
| awk '{print "open "$NF}'
open https://www.kakaofriends.com/kr/products/groups/characters/8
open https://www.kakaofriends.com/kr/products/groups/characters/23
명령어 실행
위에서 생성한 명령어를 실행할 수 있도록 스크립트를 변경하겠습니다.
$ cat clusters.txt \
| jq -r '.items[] | [.name, .displayName, .clusterUrl] | join("\t")' \
| fzf --multi --reverse \
| awk '{print "open "$NF}' \
| { while read CMD; do
eval "${CMD}"
done }
이 코드를 실행하면 여러분이 선택한 클러스터의 URL이 기본 웹브라우저에서 열릴 것입니다. 이 예제에서는 이해를 돕기 위해 각 카카오 프렌즈의 상품페이지로 이동하도록 URL을 편집해 두었습니다. ^^;
이번엔 조금 더 복잡한 구현을 도전해 볼까요?
웹 브라우저로 각 URL을 열기 전에 TMUX로 선택한 URL의 수만큼 윈도우를 분할한 후 URL 정보를 화면에 출력하도록 스크립트를 보강하겠습니다.
$ cat clusters.txt \
| jq -r '.items[] | [.name, .displayName, .clusterUrl] | join("\t")' \
| fzf --multi --reverse \
| awk '{print "echo \""$1": " $NF"\" && open "$NF";echo -n Press enter to finish.; read"}' \
| { while read CMD; do
tmux -2 split-window "${CMD}"
tmux -2 select-layout tiled
done } && tmux setw synchronize-panes on && exit
위와 같이 실행하면 여러분의 터미널 윈도우가 아래와 같이 분할된 후 URL에 출력되는 것을 확인할 수 있을 것입니다.
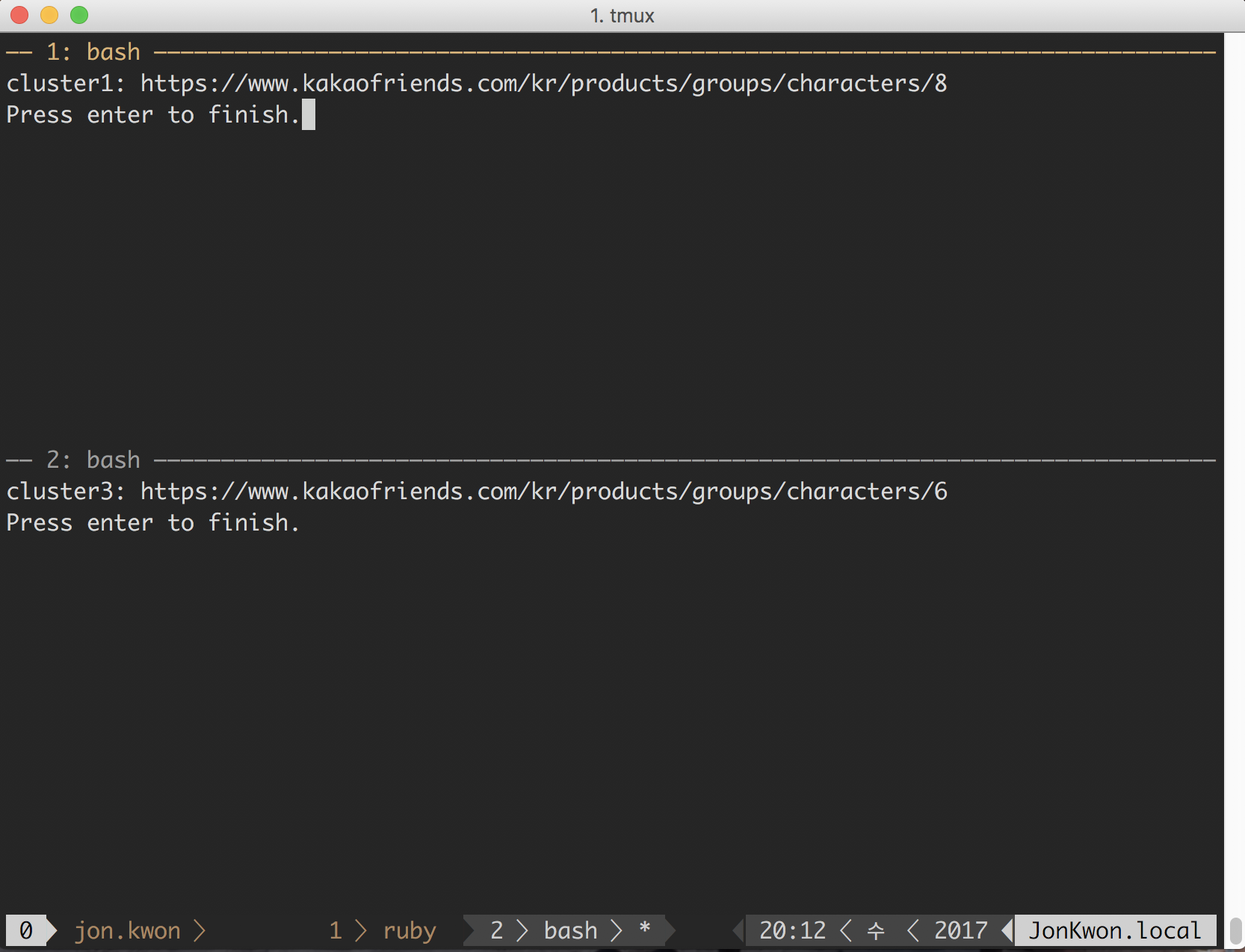
참고
CMUX에서는 이 부분이 tws 라는 별도의 명령어로 보다 정밀한 화면 제어가 가능하도록 구현되어 있습니다.
맺음말
CMUX를 개발한 후, 지난 1년여 동안 내부적으로 사용하면서 버그를 수정하고 기능을 보강하고 있지만 부끄러울 정도로 부족한 면이 많습니다. 하지만, CLI에서도 이런 것도 할 수 있다는 아이디어를 공유하고 싶었으며, 더 기발한 아이디어로 CLI가 풍부해지길 기대하면서 오픈 소스로 공개하게 되었습니다.