Overview
대부분의 초기 스타트업은 컨텐츠를 저장할 저장소에 대한 별다른 고민을 하지 않습니다. 여유가 있다면 NAS 장비를 구매해서 사용하고, 아니라면 NFS와 RAID를 구성해서 사용하게 됩니다. 하지만 서비스가 점점 커짐에 따라 하루 동안 저장되는 컨텐츠의 용량이 커지고, 네트워크 트래픽과 디스크 I/O가 증가하면서 NFS, NAS로는 유지가 불가능한 상황에 처하게 됩니다.
구글(GFS, 2003)1과 페이스북(Haystack, 2011)2도 비슷한 상황을 겪었고 자체적으로 스토리지 시스템을 만들어 서비스를 유지시키는 데 성공하였습니다. 카카오 역시 초창기엔 카카오톡에서 주고받는 이미지와 동영상들을 모두 NAS에 저장하는 방식을 채택하였지만 이용자 수와 트래픽이 늘어남에 따라 더 이상 감당할 수 없게 되었고, 이에 확장이 용이하고 빠른 응답속도와 높은 신뢰성을 가지는 대규모 분산 스토리지 시스템을 구축하게 되었습니다.
그리하여 탄생하게 된 것이 바로 KAGE(KAkao storaGE)입니다.

Introduction of Kage
현재 카카오톡, 카카오스토리를 포함해 카카오의 다양한 서비스를 지탱하고 있는 Kage의 주요 특징은 아래와 같습니다.
- 한 데이터를 3벌씩 3서버에 나누어 저장
- 데이터 저장 시 커다란 청크 파일 하나에 데이터를 쓴 후, 데이터의 위치가 담긴 Kage-Key를 리턴
- 발급받은 Kage-Key를 이용하여 저장된 데이터에 대한 읽기 및 수정이 가능.
- 청크에는 Expire-Time이 존재하여 일정 시간이 지나면 청크에 담긴 파일이 모두 삭제
Haystack와 같은 분산 스토리지의 아키텍쳐를 알고 계신 분이라면 위 특징만 보고도 어느 정도 구조가 파악되셨을 것 같습니다만, Kage 역시 보통의 분산 시스템처럼 파일을 저장할 때 복제본을 생성하여 물리적으로 다른 위치에 있는 3개의 저장소에 각각 저장합니다. 즉 원본 파일 외에도 2개의 복제본을 더 생성하여 총 3개의 파일을 저장하는 것인데, 이러한 정책을 통해 파일 읽기에 대한 트래픽을 분산시킬 수 있으며, 장애에 대한 유연한 처리도 가능해집니다. 만약 3개의 저장소 중 2개의 저장소에 장애가 발생하더라도, 나머지 하나의 저장소를 통해서 읽기 요청을 처리할 수 있습니다.
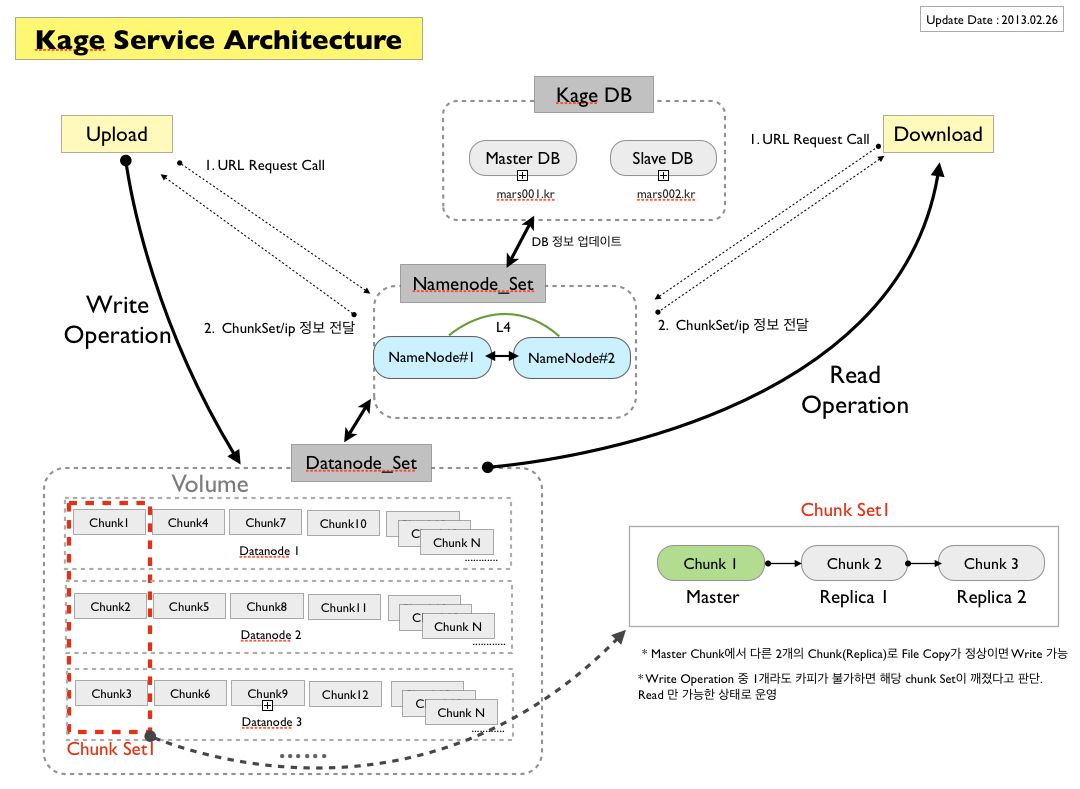
Kage는 크게 다수의 데이터노드(Datanode) 서버와 네임노드(Namenode) 서버로 구성되는데, 이 중 데이터노드는 실제 파일을 저장하고, 저장된 파일을 읽어서 전송하는 역할을 합니다. 데이터노드에 있는 파일 저장소는 청크(Chunk)라는 일정한 크기를 가진 저장공간으로 이루어져 있으며, 물리적으로 다른 서버에 있지만 논리적으로는 같은 데이터를 가지고 있는 3개의 청크를 청크셋(ChunkSet)이라고 부릅니다.
위에서 Kage가 파일을 저장할 때 서로 다른 3개의 저장소에 복제본들을 저장한다고 하였는데, 파일을 저장할 청크셋을 결정해주기만 하면 자연스럽게 3개의 서로 다른 저장소(= 청크)에 복제본을 저장할 수 있게 됩니다. 이 중 가장 먼저 데이터 쓰기를 받는 저장소를 마스터(Master), 나머지 두 노드를 슬레이브(Slave)라 부릅니다. 그렇다면 파일을 어느 청크셋에 저장할지는 누가 결정할까요? 바로 네임노드입니다.
네임노드는 실제 파일이 저장되어있는 데이터노드, 청크 그리고 청크셋들의 정보를 관리하는 역할을 합니다. 클라이언트는 데이터를 쓰기 위해서 먼저 네임노드에게 쓰기 가능한 청크셋의 정보를 요청합니다. 이후 전달받은 정보를 통해 해당 청크셋의 마스터 데이터노드에 쓰기를 요청하게 되고, 마스터는 먼저 자신의 하드디스크에 쓰기를 완료한 후에, 나머지 슬레이브 노드에 데이터를 전달합니다. 모든 쓰기 과정이 성공적으로 완료되면 Kage-Key를 받게 되는데, Kage-Key에는 청크셋ID와 오프셋 등 파일을 찾을 수 있는 정보가 담겨있습니다. 클라이언트는 이후에 이 Key를 이용해 데이터노드에 읽기 혹은 삭제 요청을 진행할 수 있습니다.
Kage-Key
읽다 보니 일반적인 파일 쓰기와 조금 다른 점을 느끼신 분들도 있을 텐데요, 일반적인 쓰기의 경우 파일 이름, 내용, 그리고 저장 위치로 쓰기를 요청하는 반면, Kage의 경우 파일 이름과 내용만으로 쓰기를 요청하고 파일이 저장된 위치(KAGE_KEY)를 돌려받습니다.
일반적인 쓰기:
Write('/tech/articles/', 'q.txt', '아이유님은 언제쯤 판교에 방문해주시나요?');
-> Response(RESULT_CODE)
Kage의 쓰기:
Write('q.txt', '아이유님은 언제쯤 판교에 방문해주시나요?');
-> Response(RESULT_CODE, KAGE_KEY)
전통적인 파일 시스템을 이용하는 NAS에서 파일을 읽게 되면 하나의 파일 읽기 요청에 대해서도 여러 번의 IO 오퍼레이션이 발생하게 됩니다. 파일 이름을 inode번호로 변환하고, inode를 디스크에서 읽고, 실제 파일내용을 디스크로 읽는 등의 과정을 거쳐야 합니다. 파일 시스템은 파일마다 메타정보(이름, 디렉토리 등)를 가지고 있고, 파일 개수가 많아질 수록 이러한 메타정보가 큰 병목이 됩니다.2 Kage는 커다란 파일(Chunk)에 순차적으로 데이터를 쓰고, Kage-Key를 통해 데이터의 논리적 위치를 구해내어 바로 접근하게 함으로써 이러한 병목 문제를 해결하였습니다.
발급받은 Kage-Key는 모두 서비스쪽에서 관리를 하여야 하는데, 혹시나 서비스쪽에서 Key를 분실한다면 영영 데이터를 찾을 수 없는 문제도 있습니다. 하지만 동시에 해당 서비스 담당자 외에는 (Kage 개발자 조차) 특정 파일이 어디에 저장되어있는지 전혀 유추할 수 없다는 보안적 장점도 가지고 있습니다.
Expire 기능
Kage의 또 다른 재미있는 특징은 일정 시간이 지나면 파일이 자동으로 삭제되도록 설정할 수 있다는 것입니다. 카카오톡의 이미지, 비디오 전송을 위해서 개발이 시작되었기 때문에 일정 시간이 지나면 청크를 삭제하며 디스크를 끝없이 재활용할 수 있게 설계되었습니다.
이 특성 때문에 청크들이 시간에 따라 삭제되고 다시 생성되는 과정이 끊임없이 반복되는데, 이 과정에서 갑자기 청크가 부족하거나, 특정 데이터노드에 트래픽이 몰리거나, 한꺼번에 많은 청크가 삭제되는 등의 현상이 발생하곤 했습니다.
자칫하면 큰 장애로 이어질 수 있는 이러한 문제들을 해결하기 위해, 청크를 할당하는 스케쥴링 방법을 다양하게 세워 최대한 노드에 트래픽이 골고루 분산될 수 있도록 하였습니다. 현재 주로 사용하고 있는 스케쥴링 방법은 아래와 같습니다.
- 청크의 평균 사용량이 N% 이상일 때
- 쓰기 가능한 청크가 N개 이하 일 때
- 가장 사용량이 적은 청크의 사용량이 N% 이상일 때
IDC 이중화 정책
Kage는 안정적인 서비스를 위해서 모든 노드들을 빠짐없이 이중화 혹은 삼중화하여 운영하고 있습니다. 또한 특정 IDC에서 문제가 생겼을 때에 발생하는 장애를 최소화하기 위해, IDC 이중화도 함께 진행하고 있습니다.
청크셋을 구성하는 대부분의 청크들 역시 두 IDC에 포함하도록 구성하고 있는데 여기에 재미있는 정책이 있습니다. Kage의 데이터는 Master->Slave->Slave 순으로 쓰이게 되는데, Master와 두 Slave의 IDC를 다르게 선택하는 정책을 사용하고 있습니다.
예를 들어 Master가 IDC-A에 있는 데이터노드라면, 나머지 두 Slave는 IDC-B에 있는 데이터노드에서 선택하는 것입니다. 이는 특정 IDC의 장애나 IDC 간의 단절이 발생했을 때 쓰기 실패를 좀 더 빨리 감지하기 위해서입니다.
IDC-B에 장애가 발생했을 때 쓰기 시나리오
(1) IDC-A(Master) -> IDC-A(Slave) -/> IDC-B(Slave)
(2) IDC-A(Master) -/> IDC-B(Slave) -> IDC-B(Slave)
(1), (2) 모두 쓰기 실패이지만, (2)의 경우에 좀 더 빨리 실패를 감지할 수 있다.
하지만 모든 청크셋이 여러 IDC에 걸쳐 있다면 IDC 단절 시 쓰기가 무조건 실패하는 문제가 발생하게 됩니다. 따라서 같은 IDC에 있는 데이터노드들로만 구성된 청크셋도 유지하여 하나의 IDC로도 서비스가 가능하게 운영하고 있습니다.
네임노드 역시 인터링크를 거치지 않고 데이터를 전달하기 위해 각 IDC 별로 하나 이상 존재합니다. 빠른 데이터 전달과 장애 극복을 위해 네임노드는 다음과 같은 우선순위를 이용해 쓰기 가능한 청크셋을 고릅니다.
1. Multi IDC이고 Master가 네임노드와 같은 IDC에 있는 청크셋
2. Multi IDC이고 Master가 네임노드와 다른 IDC에 있는 청크셋
3. Single IDC이고 Master가 네임노드와 같은 IDC에 있는 청크셋
4. Single IDC이고 Master가 네임노드와 다른 IDC에 있는 청크셋
이미지 변환과 동영상 트랜스코딩 지원
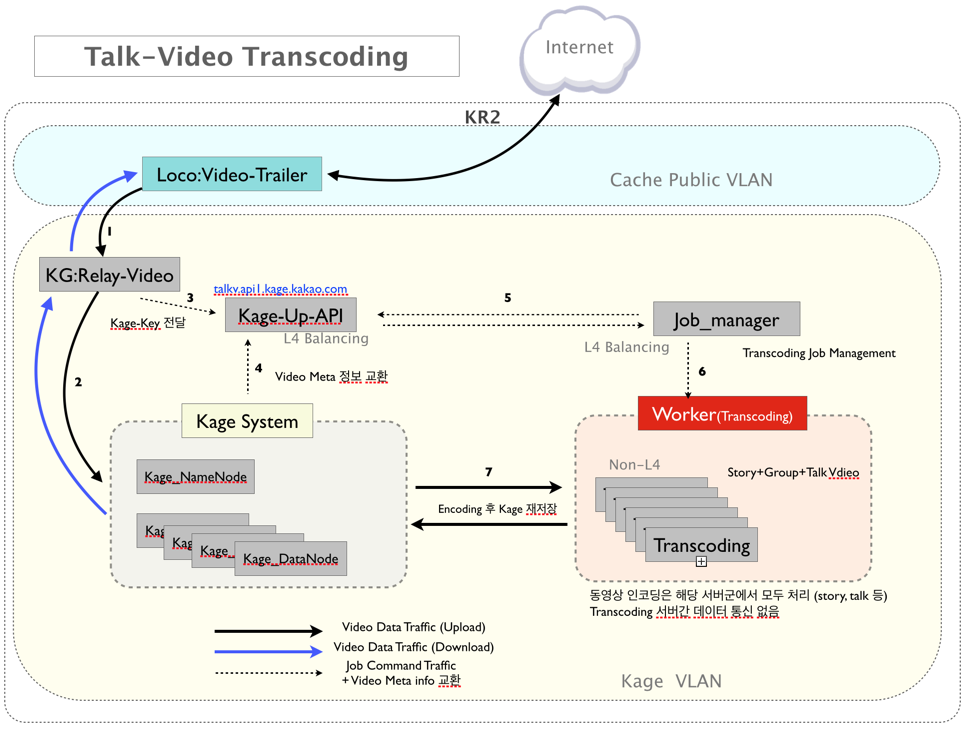
사내에 다양한 서비스들이 생기고 다양한 종류의 미디어 파일이 업로드됨에 따라, 이에 대한 전처리 혹은 후처리까지 지원하는 API서버의 필요성이 높아지게 되었습니다. 특히 비디오 파일은 모든 기기에서 원활하게 재생 가능하기 위해 트랜스코딩을 하는 과정이 필요합니다. 이 과정을 클라이언트에서 진행할 경우 너무 시간이 오래 걸려 사용자에게 좋지 않은 경험을 주게 때문에, Kage에 업로드되는 동영상의 경우 모두 서버단에서 트랜스코딩을 거쳐서 저장되고 사용자들에게 제공되게 됩니다. 현재 컨테이너 기반의 Worker 서버들이 FFMPEG을 이용해 분산 트랜스코딩을 진행하고 있습니다. 트랜스코딩의 대략적인 흐름은 아래와 같습니다.
1. 임시 저장소에 원본 동영상을 업로드
2. Worker 서버들이 영상의 일부를 트랜스코딩한 후 조각 파일을 임시 저장소에 업로드
3. 2의 과정이 모두 완료되면 임시저장소에 저장된 조각 파일들을 합친 후 실제 저장소에 업로드
4. 1~3의 과정은 자체 개발한 Job-Queue와 FUSE API를 이용하여 진행
이미지의 썸네일 생성이나 서비스마다 필요한 다양한 이미지 효과 처리를 위해서 업로드 혹은 다운로드 시에 이미지를 변환하는 기능도 제공하고 있습니다. API 서버는 HTTP 프로토콜로 Kage로 업로드 및 다운로드가 가능하고 설정에 따라 한 번의 업로드로 다양한 종류의 이미지를 얻어 낼 수 있기 때문에, 모든 서비스 개발자들은 이 API 서버를 통해 Kage를 이용하고 있습니다.
새로운 SNS 서비스를 만들어서 프로필 사진을 업로드한다고 가정해봅시다. 혹시 모르니 원본도 저장하여야 하고, 빠른 이미지 서빙을 위해 JPEG이나 WEBP로 압축된 파일도 필요하고, 썸네일도 필요하고, 어쩌면 얼굴 부분만 자른 사진도 필요할 것입니다. 큰 작업이 아니라고 생각될 수도 있으나 매 서비스마다 비슷한 개발을 진행하여야 한다면, 전사 차원에선 큰 리소스 낭비가 아닐 수 없습니다. 따라서 서비스 개발 시에 필요한 이미지 관련 처리들은 Kage API 서버에서 전담하여 처리하고 있습니다.
Object Storage: Meta-Kage
카카오의 클라우드 서비스(Krane)가 개발되면서 오브젝트 스토리지(Object Storage)에 대한 필요성이 생겼고, 이 때문에 파일의 메타정보까지 저장하는 Meta-Kage라는 시스템이 탄생하게 되었습니다. 오브젝트 스토리지는 실제 데이터와 메타 데이터를 분리하여 저장하며, 주로 사용자 계정마다 고유 식별자를 통해 파일에 접근하는 형태의 스토리지입니다. 기존의 블록 스토리지보다 성능은 떨어지지만 훨씬 많은 양의 데이터를 효율적으로 저장할 수 있다는 장점을 가지고 있습니다. 대표적인 오브젝트 스토리지 서비스로는 Amazon의 S3가 있습니다.
Meta-Kage를 단순하게 풀어보자면 실제 파일을 저장하는 Kage와 파일의 메타 정보를 저장할 Key-Value Store를 조합한 형태로 볼 수 있습니다. 만약 사용자가 “loen/image/iu.jpg”라는 파일을 Meta-Kage에 저장하기를 요청한다면 API 서버는 Kage에 파일을 써서 Kage-Key를 얻은 후에, Key-Value Store에 (“loen/image/iu.jpg”, Kage-Key)를 기록합니다. 이후에 읽기가 요청된다면 Key-Value Store에서 “loen/image/iu.jpg”에 해당하는 Kage-Key를 찾은 후에 Kage에서 해당 데이터를 읽어 요청자에게 전달하게 됩니다.
Meta-Kage는 OpenStack의 Swift API를 지원하도록 개발되었으며 현재 사내의 오브젝트 스토리지, Docker Hub 등을 포함해 비교적 업로드가 적은 서비스에서 주로 이용하고 있습니다.
Cold Storage: Cave
SNS에 업로드되는 이미지나 비디오는 시간이 흐를수록 접근 빈도가 크게 떨어지는 특징을 가지고 있습니다. 업로드 한지 얼마 되지 않아 많은 인기를 끌고 있는 (= 많은 읽기 요청을 받는) Data를 Hot Data라고 부르고, 반면 시간이 많이 흘러 인기가 식어버린 데이터를 Cold Data라고 부릅니다.

Hot Data는 많은 읽기 요청 트래픽 및 장애에 버티기 위해 보통 2벌 정도 더 복제해서 저장하는데, 모든 데이터를 원본 크기에 3배가 되는 용량으로 유지하는 것은 기업 입장에서 큰 비용입니다. 카카오톡에서 업로드된 데이터들은 일정 시간이 지나면 지워지기 때문에 상관이 없지만, 카카오스토리와 같은 서비스에 업로드 된 데이터는 영구적으로 고객들에게 제공되어야 하니 부담이 아닐 수 없습니다. 그렇다고 원본만 남기고 나머지를 지워버리기엔 하드디스크의 장애의 위험이 있기 때문에, ‘비교적 적은 용량으로 데이터를 신뢰성 있게 유지 보관하는’ Cold Storage의 필요성이 높아졌습니다. 그래서 기존 Kage 시스템을 바탕으로 Replication Factor 1.5로 데이터를 저장하는 Cave(고대 문서는 꼭 동굴에서 나오니깐…)가 탄생하게 되었습니다.
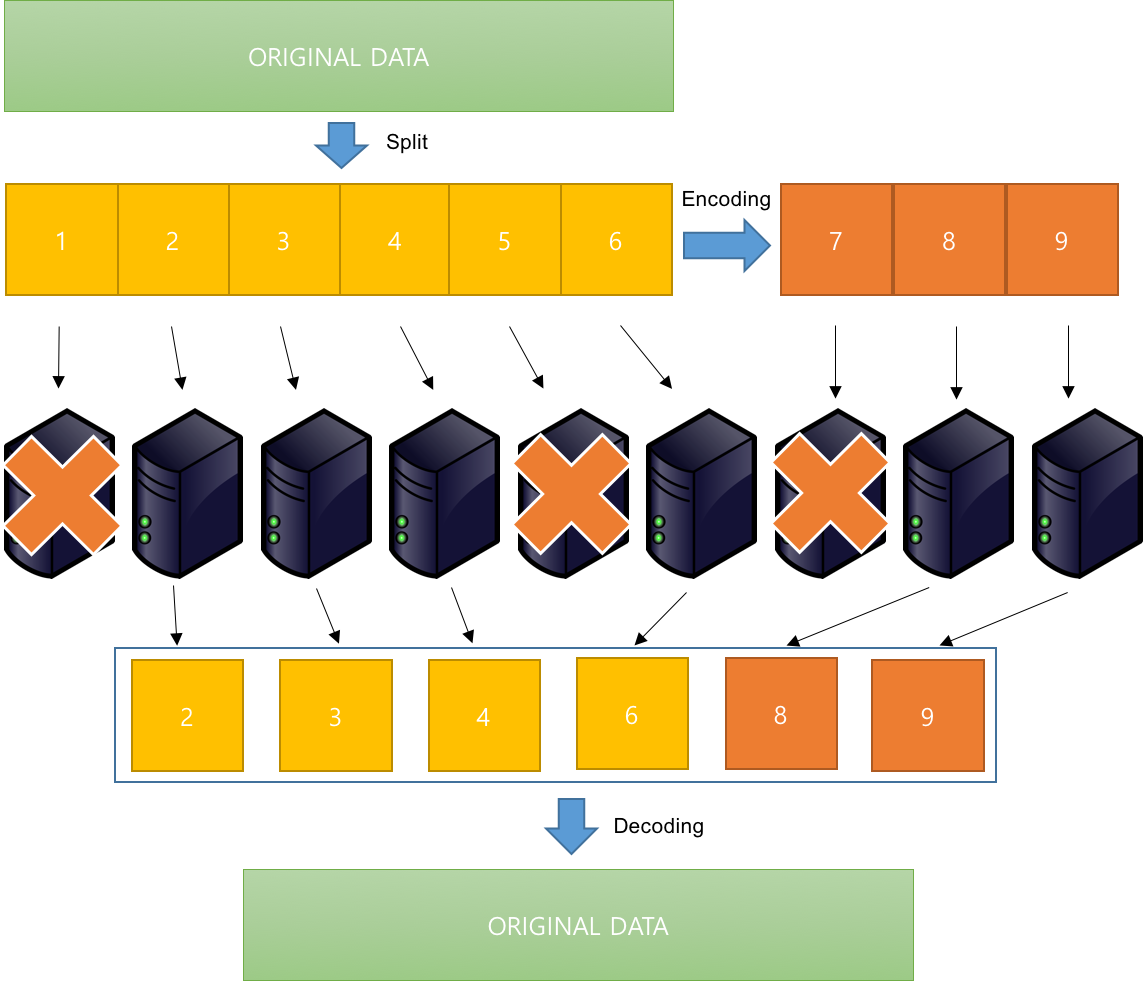
Cave 역시 기존 Kage 시스템을 바탕으로 개발되었습니다. 다만 기존 Kage에서 데이터를 저장할 땐 Replication Factor가 3이었는데 (2벌을 복제하여 총 3벌을 저장), Cave는 Replication가 1.5입니다. ‘1.5라고 하면 원본을 제외하고 반쪽만 더 저장하는 거 아닌가?’라고 생각할 수 있겠지만 1/3 정도 맞는(?) 이야기입니다. Cave는 데이터를 6개의 블럭으로 나눈 후, Reed-Solomon Coding3을 이용하여 3개의 블럭(Parity Block)을 더 만들어 냅니다. 그리고 만들어진 9개의 블럭을 9개의 Datanode에 나누어 저장합니다
이렇게 만들어진 9개의 블럭 중에 6개의 블럭만 있으면 Reed-Solomon decoding을 이용해 원본 데이터를 만들어 낼 수 있기 때문에, (Replication Factor = 9/6 = 1.5) 읽기 요청 시에 6개의 블럭만 읽어들여 원본 데이터를 만들어낸 후 유저들에게 제공하게 됩니다. 3개의 디스크에 장애가 발생하는 경우에도 문제없이 데이터를 제공하는 게 가능하며, 에러가 발생한 블럭들을 복구해 낼 수 있습니다.
카카오스토리처럼 영구 저장되는 데이터는 시간이 지나면 Cave로 마이그레이션 된 후, 데이터에 접근할 수 있는 새로운 키(Cave-Key) 새로 발급받게 됩니다. 하지만 서비스 개발자나 유저들은 기존의 Kage-key로도 Cave로 이동한 데이터를 읽을 수 있어야 하므로, 마이그레이션 시 (Kage-key, Cave-key) 쌍을 Key-value Store에 기록해둡니다. Cave가 구축된 이후부터 API 서버는 아래와 같은 방식으로 데이터를 읽고 있습니다.
1. 클라이언트에서 Kage-key로 API 서버에 읽기를 요청
2. API 서버는 Kage-key로 Key-value Store에 GET을 요청(1ms 이내의 반응속도 보장)
3. GET이 성공한다면) 리턴받은 Cave-key를 이용해 Cave에 읽기 요청
GET이 실패한다면) Kage-key를 이용해 Kage에 읽기 요청
4. API 서버는 전달받은 데이터를 클라이언트에게 전달
마치며…
지금까지 카카오의 여러 서비스들이 사용하고 있는 분산 스토리지 시스템의 발전 과정에 대해 알아보았습니다. 처음에는 NAS를 대체하기 위해 만든 단순한 형태의 스토리지 시스템이었지만 다양한 니즈에 의해 멀티미디어 지원, 오브젝트 스토리지, 콜드 스토리지 등의 형태로 발전하게 되었습니다. 전반적인 컨셉과 발전과정을 설명하는 것이 목적이었던 글이었기 때문에, 이론적 배경이나 설명이 다소 부족한 감이 있습니다. 나중에 기회가 된다면 한번 자세히 다뤄보도록 하겠습니다. ^^