KEMI(Kakao Event Metering & monItoring)는 카카오의 전사 리소스 모니터링 시스템 입니다. 서버, 컨테이너와 같은 리소스의 메트릭 데이터를 수집해서 보여주고 설정한 임계치에 따라 알림을 보내주는 KEMI-STATS과 ETL을 통해 수집한 log를 대시보드 형태로 보여주거나 실시간 알림을 할 수 있는 KEMI-LOG로 구성되어 있습니다.
KEMI-STATS
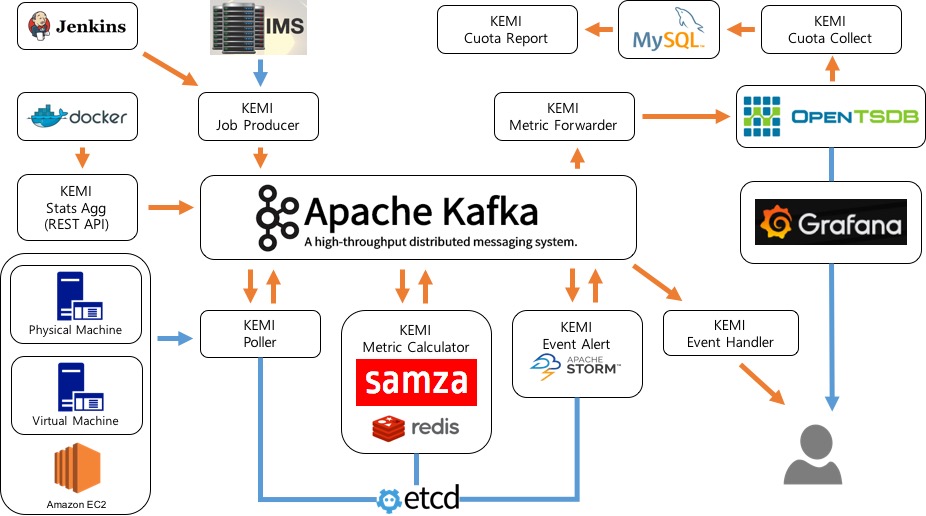 KEMI-STATS는 수만대에 이르는 카카오의 전체 서버와 컨테이너 서비스를 모니터링하는데 이용되고 있으며 polling방식과 push방식 두가지를 사용합니다.
리소스 중 서버(physical machine, virtual machine, amazon ec2)의 경우 polling방식으로 SNMP를 이용하여 시스템 메트릭을 수집합니다.
데이터를 수집하는데 여러가지 방식이 있을 수 있지만 SNMP를 기본으로 선택한 이유는 서버의 운영체제와(linux/windows/nw switch) 상관없이 모니터링하기 위해서 입니다.
KEMI-STATS는 수만대에 이르는 카카오의 전체 서버와 컨테이너 서비스를 모니터링하는데 이용되고 있으며 polling방식과 push방식 두가지를 사용합니다.
리소스 중 서버(physical machine, virtual machine, amazon ec2)의 경우 polling방식으로 SNMP를 이용하여 시스템 메트릭을 수집합니다.
데이터를 수집하는데 여러가지 방식이 있을 수 있지만 SNMP를 기본으로 선택한 이유는 서버의 운영체제와(linux/windows/nw switch) 상관없이 모니터링하기 위해서 입니다.
polling 방식의 수집은 젠킨스 배치 job을 이용해서 1분마다 아래와 같은 순서로 실행됩니다.
- job이 시작되면 KEMI의 Job Producer가 IMS(Infrastructure Management System)라는 카카오 인프라 관리 시스템에서 데이터를 가져올 대상을 받아와서 kafka의 polling job queue topic에 넣어 놓습니다. (이렇게 매 주기마다 호스트 목록을 새로 가져오는 이유는 서버가 추가되거나 빠지는걸 바로 반영하기 위해서 입니다.)
- polling job queue topic을 보고 있던 KEMI의 Poller가 각 대상들에서 시스템 메트릭을 가져와서 다시 kafka에 저장합니다. (이때 그 호스트가 속한 서비스가 어떤 메트릭들을 수집할지를 etcd에 저장해 두고 사용합니다. 그래서 추가로 필요한 메트릭이 있을때 Poller를 재시작하지 않고도 etcd에 있는 정보만 업데이트하면 수집할 수 있습니다.)
- 이 데이터들은 값을 그대로 이용할 수 있는 것(CPU usage 등)과 계산이 필요한 것(DISK usage 등)의 2종류가 있게 되며 samza를 이용한 KEMI의 Metric Calculator가 계산이 필요한 것은 계산을 해서 그외 는 그대로 다시 kafka에 넣게 됩니다.
push 방식의 수집은 컨테이너 리소스 모니터링과 SNMP가 지원되지 않는 서버에서 사용되고 있으며 아래와 같은 순서로 실행됩니다.
- 시간, 리소스 아이디, 시스템 메트릭을 KEMI의 Stats Agg로 push
- KEMI의 Stats Agg에서는 이 메트릭들을 kafka에 저장합니다.
- 일부 계산이 필요한 메트릭은 polling방식과 마찬가지로 KEMI의 Metric Calculator에 의해 계산되어 저장되고 그외 메트릭은 그대로 kafka에 저장됩니다.
polling 또는 push방식으로 수집된 데이터는 아래와 같은 순서로 View를 위해 Time Series DB에 저장되고 룰에 따라 알람이 수행됩니다.
- 준비된 최종 데이터는 KEMI의 Metric Forwarder를 통해서 OpenTSDB에 저장됩니다. (OpenTSDB에 들어간 데이터는 Grafana를 이용하여 사용자들이 그래프 형태로 볼수 있게 됩니다.)
- KEMI Event Alert를 통해서 etcd에 정해진 룰에 따라 알람 이벤트를 생성하여 다시 kafka에 넣습니다. (CPU 사용량이 90% 이상라던가 네트워크 트래픽이 떨어졌다던가 할때 개별 호스트 단위/여러 호스트를 묶은 서비스 단위로 알람 이벤트를 생성할 수 있습니다.)
- KEMI Event Handler는 kafka에 생성된 알람 이벤트를 가지고 kakaotalk, custom api 호출 등의 알람 서비스를 제공합니다.
이게 KEMI-STATS의 기본적인 구성입니다.
그리고 위의 실시간 스트리밍 데이터를 이용한 알람 외에 수집된 데이터를 이용한 리소스 효율화 서비스도 제공하고 있고 그 순서는 아래와 같습니다.
- Cuota Collect를 이용해서 주기적으로 특정 시간 간격의 데이터를 샘플링하여(시간당 max/min 값) MySQL에 저장합니다.
- MySQL의 샘플링 데이터를 Cuota Report가 확인해서 실제 서버의 사용량을 확인하고 이 중 사용량이 작은 VM(Virtual Machine)을 주기적으로 파악해서 담당자에게 알림을 주어서, 해당 VM을 삭제하거나 다른 VM들과 통합하게 함으로써 시스템을 보다 효율적으로 사용하는데 이용하고 있습니다.
이 외에도 SNMP의 oid를 확장하여 SNMP에서 제공해주는 기본 메트릭 외에 다양한 커스텀 메트릭을 수집할 수 있고, push방식으로 메트릭 데이터를 넣을 때 사용자가 만든 메트릭을 넣을 수 있습니다. 현재 KEMI-STATS의 이러한 확장성을 이용해서 시스템의 보드의 온도, haproxy, nginx, memcached, redis 등의 stats 정보, 컨테이너 등의 상태를 모니터링하기 위해 필요한 커스텀 메트릭이 수집되고 있습니다.
KEMI-LOG
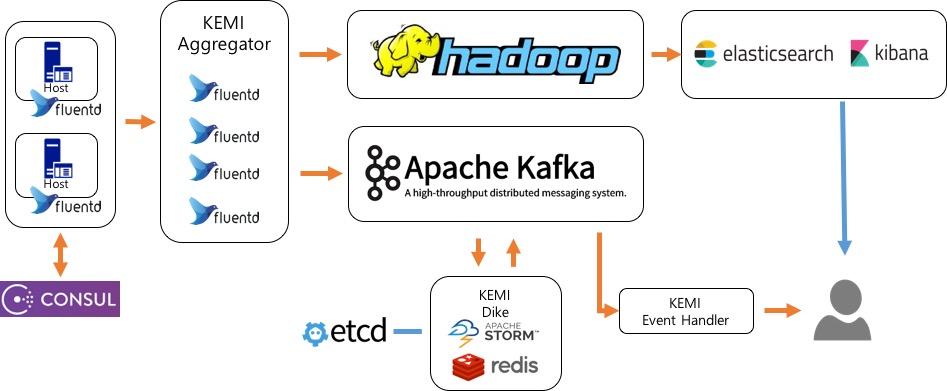 KEMI-LOG는 각 서비스에서 발생한 로그를 모아서 저장하고 보여주는 기능과 로그 별로 설정된 룰에 따라 알람을 발생시켜 줍니다.
인프라운영에 필요한 기본적인 syslog나 네트워크 관련 로그들을 받고 있으며, 필요에 따라 각 서비스들에서 KEMI-LOG쪽으로 로그 데이터를 보내서 이용하고 있으며 그 규모는 하루 수백기가 정도입니다.
KEMI-LOG의 데이터 흐름은 아래와 같습니다.
KEMI-LOG는 각 서비스에서 발생한 로그를 모아서 저장하고 보여주는 기능과 로그 별로 설정된 룰에 따라 알람을 발생시켜 줍니다.
인프라운영에 필요한 기본적인 syslog나 네트워크 관련 로그들을 받고 있으며, 필요에 따라 각 서비스들에서 KEMI-LOG쪽으로 로그 데이터를 보내서 이용하고 있으며 그 규모는 하루 수백기가 정도입니다.
KEMI-LOG의 데이터 흐름은 아래와 같습니다.
- 서비스 별 로그의 경우 각 서버에 설치된 fluentd를 이용하고 syslog나 네트워크 관련 로그는 syslog의 target 설정을 통해 consul domain 으로 엮여진 KEMI Aggregator로 전달됩니다.
- 이렇게 보내진 데이터는 KEMI-LOG에 aggregator 역할을 해주는 fluentd 서버그룹들이 받은 다음에 그 로그들을 각각 hadoop, kafka에 넣어줍니다.
- hadoop에 저장된 데이터는 hive batch job을 통해 주기적으로 (5~15분) elasticsearch cluster로 indexing되며 kibana를 통해 사용자가 조회할 수 있게 됩니다.
- kafka에 저장된 데이터는 etcd의 알람 룰과 STORM, redis를 활용해 개발된 KEMI Dike를 통해 실시간으로 알림을 발생시킵니다.
위 데이터 흐름에서 선택하거나 개발된 몇가지 기술들과 방법은 아래와 같은 장점을 가집니다.
- fluentd는 다양한 플러그인들이 존재해서 간단한 설정만으로도 손쉽게 원하는 형태로 로그 데이터를 변환해서 주고 받을 수 있습니다.
- 전체 aggregator 호스트를 service discovery 도구인 consul로 관리되는 도메인을 바라보게 되어 있어서, 각 서버에 있는 fluentd의 설정을 변경하지 않은채로 KEMI Aggregator에 서버를 추가하거나 빼는 작업을 할 수 있어서 손쉬운 scale in/out이 가능합니다.
- hadoop의 안정적인 데이터 저장 제공으로 elasticsearch가 문제가 생겼더라도 재처리와 bulk insert로 인해 보다 많은 양의 로그를 indexing 처리할 수 있습니다.
- 로그 알림에 사용하는 rule은 표준 SQL 형식으로 사용자가 지정할 수 있고, rule을 etcd에 저장해두기 때문에 storm topology의 재시작없이 변경사항이 동적으로 적용됩니다.
- 발생한 알림은 커스텀 메트릭의 형태로 KEMI-STATS쪽에 저장해서 대시보드를 구성해서 본다거나 KEMI-STATS과 KEMI-LOG의 통합 알림에도 사용할 수 있습니다.
KEMI 개발은 issac.lim, hardy.jung, jenny.ssong, joanne.hwang, andrew.kong 이 함께하고 있으며 카카오 인프라&데이플랫폼팀의 많은 지원을 받아 운영되고 있습니다. 끝으로… 위 내용이 모니터링 서비스를 개발하고 계신 분들께 조금이라도 도움이 되면 좋을 것 같습니다.