이번 챕터에서는 데이터 쓰기가 Block과 Page 레벨에서 어떻게 처리되는지, 그리고 쓰기 시에 발생하는 “Write Amplication”과 “Wear Leveling”의 기본적인 개념을 살펴보도록 하겠다. 추가로 FTL(Flash Translation Layer)이 무엇인지, 그리고 FTL의 2가지 목적인 논리적 블록 맵핑(Logical Block Mapping, 여기에서는 Hybrid Log Block Mapping 위주로)과 Garbage-collection도 같이 살펴볼 것이다.
3. 기본 오퍼레이션
3.1. 읽기 & 쓰기 & 삭제(Erase)
NAND 플래시 메모리의 구성 특성상, 특정 셀을 단독으로 읽고 쓰는 작업은 불가능하다. 메모리는 그룹핑되어 있으며, 아주 특별한 방법으로만 접근할 수 있다. 그래서 NAND 플래시 메모리의 특별한 방법을 숙지하는 것은 SSD의 데이터 구조를 최적화하고 작동 방식을 이해하는데 있어서 꼭 필요한 부분이다. 이번 섹션에서는 SSD의 읽고 쓰기 그리고 삭제(Erase) 오퍼레이션이 실행되는 방법들을 살펴 보도록 하겠다.
읽기는 페이지 사이즈 단위로 실행(Reads are aligned on page size)
한번에 하나의 페이지보다 작은 크기의 데이터를 읽을 수는 없다. 물론 사용자는 운영 체제에게 단 하나의 바이트만 읽기를 요청할 수는 있지만, 실제 SSD는 하나의 페이지를 통째로 읽은 다음 불 필요한 데이터는 모두 버리고 사용자가 요청한 한 바이트만 반환하는 것이다. 즉 불필요한 데이터를 많이 읽게 되는 것이다.
쓰기는 페이지 사이즈 단위로 실행 (Writes are aligned on page size)
쓰기를 실행할 때에도 SSD는 페이지 단위로, 하나의 페이지 또는 여러 개의 페이지로 실행된다. 그래서 단 하나의 바이트만 기록하는 경우에도 반드시 전체 페이지가 기록되어야 한다. 이렇게 필요 이상으로 쓰기가 발생하는 것(Write Overhead)을 “Write Amplication”이라고 하는데, 이는 섹션 3.3에서 자세히 설명하고 있다. SSD의 페이지에 데이터를 쓰는 것을 “프로그램 (program)”한다 라고도 하며, 많은 SSD 관련 문서에서 쓰기(Write)와 프로그램(Program)은 자주 혼용되기도 한다.
페이지는 덮어 쓰기(Overwrite)될 수 없다 (Pages cannot be overwritten)
NAND 플레시 메모리의 페이지는 반드시 “free” 상태일때에만 쓰기를 할 수 있다. 데이터가 변경되면, 페이지의 내용은 내부 레지스터로 복사된 후 레지스터에서 변경되어 새로운 “free” 상태의 페이지로 기록되는 것이다. 이를 “Read-Modify-Write”라고 한다. SSD에서 데이터는 다른 페이지로 이동하지 않고 변경될 수 없다(in-place update가 불가능). 이렇게 변경된 데이터가 새로운 페이지에 완전히 기록되면, 원본 페이지는 “stale”로 마킹되고 삭제(Erase)되기 전까지 그 상태로 남게 된다.
삭제(Erase)는 블록 사이즈 단위로 실행 (Erases are aligned on block size)
페이지는 덮어 쓰기가 불가능하기 때문에 한번 “stale” 상태로 된 페이지는 반드시 삭제(Erase)하는 작업을 거쳐서 “free” 상태로 전이할 수 있다. 그러나 삭제는 단일 페이지 단위로 처리될 수 없고, 그 페이지가 포함된 블록을 통째로 삭제해야 한다. 사용자는 읽기와 쓰기 명령만 데이터 액세스를 위해서 사용할 수 있으며, 삭제 명령은 SSD 컨트롤러가 “free” 공간이 필요할 때 자동적으로 내부 명령을 실행해서 Garbage-collection을 실행할 때 사용된다.
3.2. 쓰기 예제
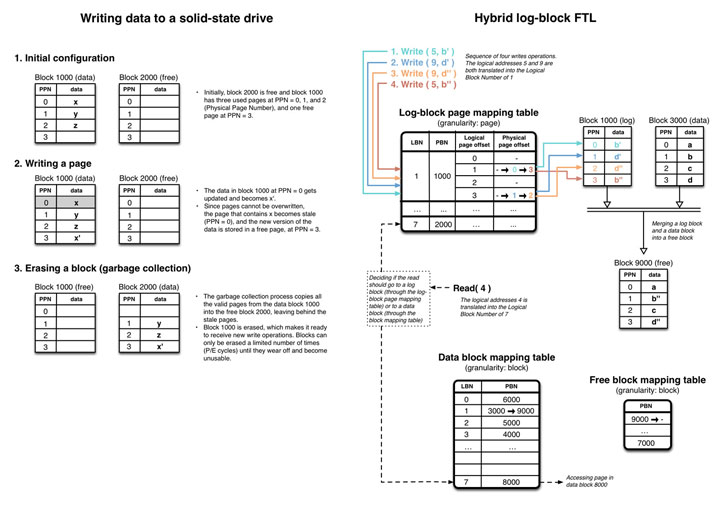
아래의 그림 4는 SSD에 데이터가 기록되는 과정을 보여주고 있다. 설명을 단순화하기 위해서, 이 그림에서는 단 2개의 블록과 각 블록의 4개의 페이지만을 가지고 있도록 그려졌지만 여전히 NAND 플래시 패키지의 전체 구성을 표현하고 있다. 그림의 각 단계에서 오른쪽의 텍스트는 어떤 일이 발생하고 있는지를 설명하고 있다.

- Initial Configuration
처음 상태로, 2000번 블록은 “free” 상태이며, 1000번 블록은 3개의 이미 사용된 “used” 페이지(PPN=0,1,2)와 1개의 “free” 페이지(PPN=3)를 가지고 있다. 여기에서 PPN은 물리 페이지 번호(Physical Page Number)를 의미한다.
- Writing a page
1000번 블록의 PPN=0 페이지가 “x’“로 업데이트되었다. 페이지는 덮어 쓰기될 수 없으므로 기존 “x” 데이터를 가진 PPN=0 페이지는 “stale” 상태로 바뀌고 새로운 버전의 데이터가 “free” 페이지였던 PPN=3 페이지로 기록되었다.
- Erasing a block
Garbage-collection은 1000번 블록의 모든 유효한 데이터(“stale” 상태의 PPN=0는 남기고)를 2000번 블록으로 복사한다. 새로운 쓰기를 받아들이기 위해서 1000번 블록은 삭제된다. 블록은 지정된 횟수(P/E cycles)만큼만 삭제 될 수 있다.
3.3. Write amplification
쓰기는 페이지 사이즈에 맞춰서(Aligned) 실행되므로, 페이지 사이즈에 일치하지 않는 모든 쓰기는 필요 이상의 부가적인 쓰기(Write amplification 1)를 필요로 한다. 한 바이트 쓰기는 결국 하나의 페이지를 통째로 쓰기해야 하므로, 페이지 사이즈가 16KB인 SSD에서는 16KB를 기록해야 하고 이는 상당히 비효율적이다.
그러나 이것만 SSD의 문제점은 아니다. 필요 이상의 데이터를 쓰게 되면, 필요 이상의 내부 오퍼레이션을 유발하게 된다. 페이지 크기에 맞춰지지 않은 쓰기는 먼저 해당 페이지의 데이터를 캐시로 읽어야 하며, 다시 페이지에 기록되어야 하기 때문에 즉시 페이지에 기록하는 것보다 느리게 작동한다. 이런 현상을 “read-modify-write”라고 하는데, 가능하다면 이런 현상은 피하는 것이 좋다 2 3.
페이지 사이즈보다 작은 데이터 쓰기는 피하자
“Write Amplication”과 “Read-Modify-Write” 현상을 최소화하기 위해서, NAND 플래시 페이지의 크기보다 작은 데이터의 쓰기는 가능하면 피하도록 하자. 현재 최대 페이지 사이즈가 16KB이므로, 16KB 이상의 데이터 쓰기를 권장한다. 이 크기는 SSD 모델에 따라서 가변적인데, 앞으로 SSD가 발전하면서 페이지의 크기가 더 증가할 수도 있고 그때에는 데이터 쓰기의 단위를 더 늘려야 할 필요도 있다.
쓰기 맞춤 (Align writes)`
데이터의 쓰기는 단일 페이지의 크기에 맞추거나, 여러 페이지의 크기에 맞춰서 실행하도록 하자.
작은 데이터의 쓰기는 버퍼링 (Buffer small writes)`
스루풋을 최대화하기 위해서, 가능하면 작은 쓰기는 메모리에 버퍼링했다가 버퍼가 가득 차면 단일 쓰기로 최대한 많은 데이터를 기록하도록 하자.
3.4. Wear leveling
섹션 1.1에서 살펴보았듯이, 프로그램-삭제(P/E Cycles) 회수가 제한되어 있으므로 NAND 플래시 셀은 제한된 수명을 가지게 된다. 예를 들어서 하나의 블록에만 데이터를 읽고 쓰는 가상의 SSD를 가정해보면, 이 블록은 아주 빨리 P/E 사이클 제한을 넘어서게 되어서 사용하지 못하게 될 것이다. 그러면 SSD컨트롤러는 이 블록을 “사용 불가능”으로 마킹하게 된다. 결과적으로 SSD의 전체 사용 가능한 공간이 줄어들게 된다. 500GB 용량의 SSD 드라이브를 구매했는데 2년 후에는 250GB 공간만 남게 된다면, 얼마나 짜증나겠는가?
이러한 이유로 SSD 컨트롤러의 중요한 역할 중 하나는, SSD의 전체 블록에 대해서 P/E cycle이 골고루 분산되도록 쓰기(“Wear leveling”)를 실행하는 것이다. 이상적으로는 모든 블록이 P/E Cycle 한계에 동시에 도달하여 한번에 모든 블록이 사용 불가능 상태로 만드는 것이다 4 5.
최고의 “Wear leveling”을 위해서, SSD는 쓰기가 발생하면 현명하게 블록을 선택해야 하며 때로는 특정 블록을 주위로 옮겨야 할 수도 있다. 이 과정에서 또 다른 “Write Amplication”이 발생하는 것이다. 그래서 블록 관리는 “Write Amplication”과 “Wear Leveling”의 사이에서 적절히 타협점을 찾아야 하는 것이다. 그래서 SSD 제조사들은 Garbage-collection과 같은 “Wear Leveling”을 위한 기능들을 가진 제품을 출시하고 있는 것이다.
Wear leveling
NAND 플래시 셀은 너무 빈번하게 쓰기 삭제 과정을 거치면 사용 불가능 상태(wearing off)가 되기 때문에, 셀 간의 작업을 분산하여 각 블록들이 P/E Cycle 한계에 동시에 도달하도록 하는 것이 FTL(Flash Translation Layer)의 중요한 목표 중 하나이다.
4. FTL (Flash Translation Layer)
4.1. FTL의 필요성
업계에 SSD가 이렇게 쉽게 받아들여지게 만든 중요한 요소 중 하나는 SSD가 HDD와 동일한 호스트 인터페이스를 이용한다는 것이다. 물론 현재의 LBA(Logical Block Address) 어레이는 덮어쓰기가 가능한 HDD에서만 적합한 요소이며, SSD에는 적합하진 않지만 말이다. 이 때문에 NAND 플래시 메모리는 내부적인 특성을 숨기고 LBA 어레이를 호스트로 노출하기 위해서 부가적인 컴포넌트를 필요로 한다. 이 컴포넌트를 FTL(Flash Translation Layer)하고 하며, SSD 컨터롤러 내부에 위치하고 있다. FTL은 아주 중요한 역할을 담당하며, 논리적 블록 맵핑(Logical Block Mapping)과 Garbage-collection 2개의 중요한 부분을 담당한다.
4.2. 논리적 블록 맵핑 (Logical block mapping)
논리적인 블록 맵핑은 호스트 영역의 논리 주소(LBA, Logical Block Address)를 NAND 플래시 메모리의 물리적 주소(PBA, Physical Block Address)로 변환해주는 역할을 담당한다. 블록 맵핑은 LBA와 PBA로 구성된 테이블을 가지며, 이 맵핑 테이블은 빠른 액세스를 위해서 SSD의 메모리(RAM)에 저장되며, 전원이 꺼지거나 만약의 경우를 대비해서 SSD의 플래시 메모리에도 저장된다. SSD의 전원이 켜지면 플래시 메모리에 저장된 맵핑 테이블을 읽어서 메모리(RAM)에 로딩된다 6 3.
블록 맵핑을 구현하는 단순한 방법은 페이지 단위로 맵핑 테이블을 구성하는 것이다. 이 방법은 아주 유연하지만, 맵핑 테이블 자체가 아주 많은 메모리를 사용하게 된다는 큰 단점이 있다. 필요한 메모리가 커지면 SSD의 생산 단가가 상당히 높아지게 된다. 이를 해결하기 위한 방법으로는 페이지 단위가 아니라 블록 단위의 맵핑을 이용할 수도 있다. SSD 드라이브가 256개의 페이지를 가지고 있다고 가정해보면, 블록 단위의 맵핑은 페이지 단위의 맵핑보다는 256배 적은 메모리를 필요로 하게 되므로 그만큼 적은 메모리가 필요하게 되는 것이다. 그러나 페이지 하나만 기록되어도 될 정도의 작은 데이터를 자주 업데이트하는 경우에는 불필요하게 블록을 통째로 기록해야 하기 때문에 불필요한 쓰기가 많이 발생하게 된다. 이는 SSD의 “Write Amplication”을 증가시키기 때문에 블록 단위의 맵핑은 상당히 비효율적이라고 볼 수 있다 6 2.
블록 레벨과 페이지 레벨 맵핑의 트레이드 오프(Trade-off)는 성능과 용량의 문제라고 볼 수 있다. 그래서 일부 연구원들에 의해서 “Hybrid” 한 방법7들이 제시되었는데, 이 중에서 가장 일반적인 방법이 Log Structrued 파일 시스템과 비슷한 형태의 Log-block 맵핑이다. 유입되는 쓰기 오퍼레이션은 시퀀셜하게 로그 블록에 기록되고, 로그 블록이 꽉 채워지면 동일한 LBN(Logical block Number)을 가지는 블록의 데이터와 병합하여 새로운 “free” 블록으로 기록하는 방법이다. 이 방법에서 로그 블록은 몇 개(a few)만 유지되기 때문에, 페이지 단위의 맵핑은 아주 소량만 관리되면 된다 8 7.
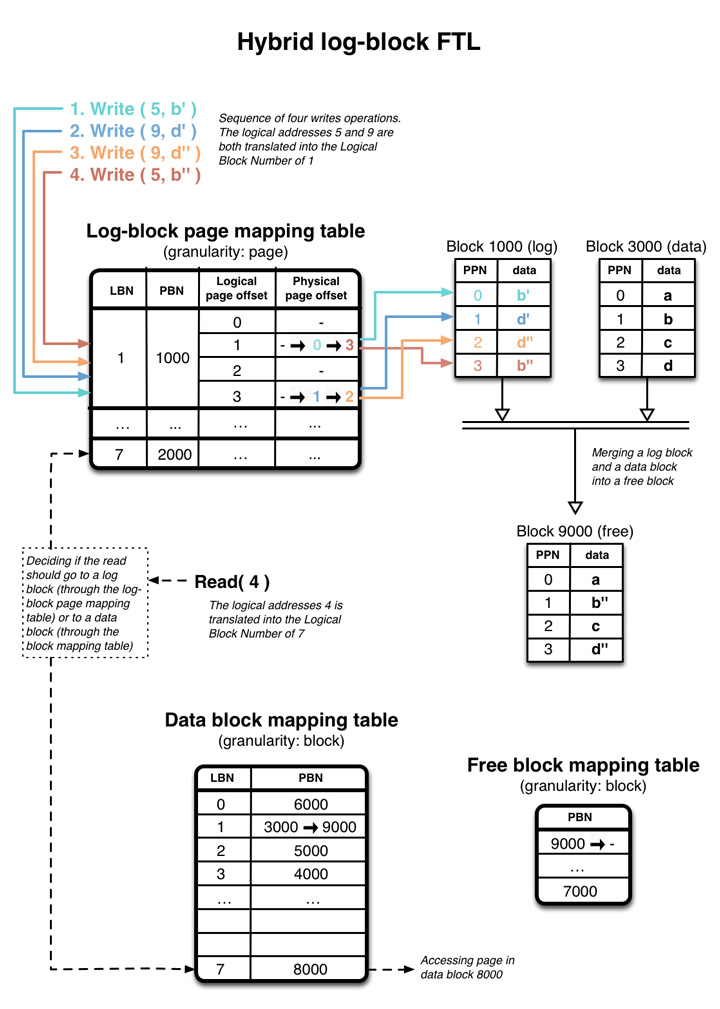
아래의 그림 5는 단순화한 Hybrid log block FTL을 보여주고 있는데,
각 블록은 4개의 페이지만을 가지고 있다.
4번의 쓰기가 FTL에 의해서 처리되고 모든 페이지들이 가득 데이터를 가지게 될 것이다.
논리적인 페이지 번호 5와 9는 LBN=1과 연결되며, LBN=1은 물리 주소 1000번과 연결되어 있다.
초기 LBN=1이 로그 블록 맵핑 테이블에 있을 때는, 모든 물리 페이지의 옵셋은 NULL이며 1000번 로그 블록은 비어 있는 상태이다.
처음 b’가 LPN=5에 기록되고 로그 블록 맵핑 테이블(PBN=1000, log block #1000)에 의해서 LBN=1로 연결된다.
즉 페이지 b’는 1000번 블록의 옵셋 0 위치에 기록된 것이다.
맵핑의 메타 데이터가 업데이트되어야 하는데, 이를 위해서 물리 옵셋이 논리 옵셋 1(예를 들어서)의 위치에 NULL에서 0으로 저장된다.
쓰기 오퍼레이션은 계속 유입되고 그에 맞게 맵핑 메타 데이터도 변경된다.
1000번 로그 블록이 가득 채워지면, 3000번 논리 데이터 블록과 병합된다.
이 정보는 데이터 블록 맵핑 테이블을 통해서 확인할 수 있다.
병합 작업의 결과는 “free” 상태였던 9000번 블록에 기록되는데,
이 작업이 끝나면 1000번과 3000번 블록은 삭제(Erase)되어 “free” 블록이 되고 9000번 블록은 데이터 블록이 된다.
데이터 블록 맵핑 테이블의 LBN=1을 위한 메타 데이터는 처음 3000번 데이터 블록에서 9000번 데이터 블록으로 업데이트된다.
여기에서 중요한 것은 4번의 쓰기가 2개의 LPN에만 집중되어 있다는 것이다.
로그 블록 맵핑 방법은 병합이 진행되는 동안 “Write Amplication”을 줄이기 위해서,
b’와 d’는 무시하고 더 최신의 b”와 d”만 데이터 블록에 저장한다는 것이다.
마지막으로 로그 블록이 병합되기 전에 최근 업데이트된 데이터를 읽으려고 하면,
그 데이터는 로그 블록에서 읽어야 한다. 물론 이미 병합된 데이터라면 데이터 블록을 읽어야 할 것이다.
이 때문에 읽기 요청은 로그 블록 맵핑 테이블과 데이터 블록 맵핑 테이블을 모두 읽어야 하는 이유인데, 이는 그림 5에 보여지고 있다.
로그 블록 FTL은 더 나은 최적화를 할 수 있도록 해주는데, 그 중에서도 중요한 것은 “switch-merge”(“swap-merge”이라고도 함)이다. 논리 블록의 주소가 한번에 기록된다고 가정해보자. 이는 그 논리 주소의 새로운 데이터들이 동일한 로그 블록에 기록된다는 것을 의미한다. 이 로그 블록은 전체 논리 블록의 데이터를 모두 가지기 때문에, 이 로그 블록을 별도의 병합하여 새로운 블록으로 옮기는 과정은 불필요한 작업(병합전과 병합후의 블록이 동일한 데이터를 가지게 될 것이므로)이 될 것이다. 이런 경우에는 단순히 로그 블록 맵핑을 거치지 않고 데이터 블록 맵핑을 바로 변경할 수 있으면(데이터 블록 맵핑의 메타 데이터만 변경하면 되므로) 더 빠를 것이다. 이렇게 데이터 블록 맵핑 테이블에서 데이터 블록과 로그 블록을 바꾸는(switch) 것을 “switch-merge”라고 한다.
로그 블록 맵핑 스키마는 많은 논문의 주제가 되곤 했으며, FAST (Fully Associative Sector Translation), 수퍼 블록 맵핑 그리고 Flexible Group Mapping7 등과 같은 발전을 이루어 왔다. Mitsubishi 알고리즘과 SSR8 등의 맵핑 스키마도 있다. 아래는 FTL과 맵핑 스키마를 배우기 위한 좋은 자료들이다.
- “A Survey of Flash Translation Layer“, 정 태선 외, 20098
- “A Reconfigurable FTL (Flash Translation Layer) Architecture for NAND Flash-Based Applications“, 박 찬익 외, 2008 7
FTL (Flash Translation Layer)
FTL(Flash Translation Layer)은 호스트의 LBA(Logical Block Address)와 드라이브의 PBA(Physical Block Address)를 맵핑해주는 SSD 컨트롤러의 컴포넌트이다. 가장 최근의 드라이브는 Log Structure 파일 시스템과 같이 작동하는 “hybrid log-block mapping” 또는 그 파생 알고리즘을 구현하고 있다. 이 알고리즘은 랜덤 쓰기를 시퀀셜 쓰기처럼 핸들링할 수 있도록 해준다.
4.3. 업계 상황
2014년 2월 2일 현재 위키피디아9에는 70여개의 SSD 제조사가 나열되어 있는데, 재미있는 것은 단 11개의 제조사만 SSD 컨트롤러를 생산하고 있다. 제조사는 단 11개10만 있다. 그리고 11개의 제조사중에서 삼성과 인텔을 포함한 단 4개의 제조사만 자사를 위한 SSD 컨트롤러를 생산하고 있으며, 나머지 7개사는 SSD 컨트롤러를 생산하여 다른 SSD 제조사로 판매하고 있는 것이다. 이는 단지 7개 회사가 SSD 마켓의 90% 정도의 SSD 컨트롤러를 제공하고 있다는 것을 의미한다.
이 90%의 수치중에서 어떤 SSD 컨트롤러 회사가 어떤 SSD 드라이브 제조사로 공급하고 있는지는 모르겠지만, 파레토 법칙으로 고려해보면, 단지 2~3개의 컨트롤러 제조사가 대 부분의 시장을 점유하고 있을 것으로 보인다. 이런 이유로 삼성이나 인텔등 전용 SSD 컨틀롤러를 사용하는 4개 회사를 제외하면, 나머지 회사들의 SSD 드라이브는 거의 모두 동일한 SSD 컨트롤러를 사용중이며 매우 비슷하게 작동할 것이라는 것이다.
SSD 컨트롤러의 일부인 맵핑 스키마는 SSD 드라이브의 전체적인 성능을 결정하기 때문에 SSD의 크리티컬한 컴포넌트라고 할 수 있다. 경쟁이 심한 SSD 시장에서 서로 자사의 FTL 구현 알고리즘을 상세한 내용을 전혀 공개하지 않는 이유가 이 때문인 것이다. 그래서 FTL 알고리즘에 대한 내용들이 많이 공유되어 있지만, 얼마나 많은 제조사들이 그 FTL 알고리즘을 구현하고 있는지는 어떤 모델이나 브랜드에 적용하고 있는지 알려지지 않는다
“11 Essential roles of exploiting internal parallelism of flash memory based solid state drives in high-speed data processing, Chen et al, 2011”의 저자는 워크로드를 분석해서 SSD 드라이브가 사용중인 맵핑 알고리즘을 리버스 엔지니어링(Reverse Engineering)할 수 있다고 주장한다. 개인적으로 나는 칩으로부터 바이너리 코드 자체를 리버스 엔지니어링하지 않는 이상, 특정 드라이버에서 어떤 맵핑 정책이 사용되는지 정확히 판단하기는 어렵다고 생각한다. 또한 특정 워크로드에서는 어떤 맵핑 알고리즘이 사용되는지 예측하기는 더 어렵다.
세상에는 수많은 맵핑 알고리즘이 있으며, 그 수많은 제품들의 펌웨어를 리버스 엔지니어링한다는 것은 엄청난 시간이 소모될 것이다. 그럼에도 불구하고 맵핑 방법의 모든 소스 코드를 구했다고 한들 무슨 이점이 있을까? 종종 새로운 프로젝트를 위한 시스템의 요건은 일반적으로 교체될 수 있는 하드웨어를 이용해서 조금 더 나은 결과를 내는 것이다. 그래서 하나의 맵핑 알고리즘을 위해서 서비스를 최적화하는 것이 다른 맵핑 알고리즘에서도 좋은 성능을 보장하는 것이 아니기 때문에, 그다지 가치 있는 최적화는 아닌 것으로 볼 수 있다. 하나의 맵핑 알고리즘에만 적합한 최적화가 필요한 경우는 그 하드웨어만 지속적으로 사용해야 하는 임베디드 시스템과 같은 경우이다.
이러한 이유들로 인해서, SSD가 사용중인 맵핑 알고리즘을 알아내는 것은 큰 이점이 없다고 생각된다. 맵핑 스키마에서 한가지 알아야 할 중요한 것은 LBA와 PBA 사이의 주소 변환이며, 이를 위해서 Hybrid Log Block 맵핑 또는 그로부터 파생된 맵핑 알고리즘이다. 결과적으로 맵핑 테이블과 메타 데이터를 변경하는 오버헤드를 최소화해주기 때문에, NAND 플래시 블록의 크기보다 큰 데이터 청크를 쓰기하는 것은 효율적이다.
4.4. Garbage collection
섹션 4.1과 4.2에서 소개되었듯이, SSD 드라이브의 페이지는 덮어쓰기 될 수 없다. 만약 페이지의 데이터가 업데이트되어야 한다면, 새로운 버전의 데이터는 “free” 페이지에 기록되어야 하고 예전 버전의 데이터가 기록된 페이지는 “stale”로 삭제 마킹되어야 한다. 블록이 “stale” 상태의 페이지들을 가지고 있다면, 그들은 재사용되기 위해서는 먼저 삭제(Erase)되어야 한다.
Garbage collection
SSD 컨트롤러의 Garbage-collection 프로세스는 “stale” 상태의 페이지들이 삭제(Erase)되어 새로운 쓰기 데이터를 저장할 수 있도록 해주는 과정이다.
단순히 데이터 쓰기 오퍼레이션(250 ~ 1500 마이크로 초)에 비해서 블록을 삭제(Erase)하는 과정(1500 ~ 3500 마이크로 초)은 많은 시간이 소요되므로, 이런 부차적인 삭제(Erase) 작업은 쓰기 속도를 느리게 만든다. 그래서 일부 컨트롤러는 백그라운드 Garbage-collection을 도입하고 있다. 백그라운드 Garbage-collection은 Idle Collection이라고도 알려져 있는데, 이는 SSD 컨트롤러가 한가한 시간에 주기적으로 “stale” 페이지를 “free” 상태로 만들어 준다. 이렇게 충분한 “free” 상태의 페이지가 준비되어 있으면 유저 쓰기는 느려지지 않고 충분히 빠른 쓰기 속도를 보장할 수 있게 되는 것이다6. 다른 SSD 컨트롤러는 Parallel Garbage-collection 방식을 구현하고 있는데, 이는 호스트의 쓰기 요청과 동시에 Garbage-collection을 실행하는 방식이다1.
호스트로부터 쓰기 요청이 올 때 동시에 Garbage-collection이 필요할 정도의 과도한 쓰기 부하를 필요로 하는 워크로드는 흔하지 않다. 이런 때에는 Garbage-collection이 백그라운드로 실행되는 것은 호스트로부터 전달되는 포그라운드(Foreground) 명령 실행을 방해할 수 있다 6. TRIM 명령과 Over-provisioning은 이런 현상을 줄여줄 수 있는 좋은 솔루션인데, 이는 섹션 6.1과 6.2에서 살펴보도록 하겠다.
백그라운드 오퍼레이션은 포그라운드 오퍼레이션에 악영향을 미칠 수 있다. Garbage-collection과 같은 백그라운드 오퍼레이션은 호스트로부터 오는 포그라운드 명령에 나쁜 영향을 미칠 수 있다. 특히 이런 현상은 작은 데이터의 랜덤 쓰기가 지속적으로 발생하는 시스템에서는 더욱 더 나쁜 영향을 미치게 될 것이다.
블록이 이동되어야 하는 조금 덜 중요한 이유중 하나는 읽기 방해(Read disturb)이다. 읽기는 주의 셀들의 상태를 변경할 수도 있다. 그래서 블록은 일정 회수 이상의 읽기가 수행된 이후 다른 위치로 옮겨져야 한다5. 데이터가 변경되는 비율은 중요한 요소이다. 어떤 데이터는 아주 뜸하게 변경되는데, 이런 데이터를 콜드(cold) 또는 정적(static) 데이터라고 한다. 반면 아주 빈번하게 변경되는 데이터들도 있는데, 이를 핫(hot) 또는 동적(dynamic) 데이터라고 한다. 만약 페이지가 일부는 콜드 그리고 나머지 일부는 핫 데이터를 가진다면, Wear Leveling을 위해서 핫 데이터가 Garbage-collection될 때마다 콜드 데이터도 같이 옮겨 다녀야 할 것이다. 하지만 이렇게 핫 데이터와 함께 콜드 데이터들이 따라 다녀야 한다면, “Write Amplication”은 더 심해질 것이다. 이런 현상은 콜드 데이터와 핫 데이터를 서로 다른 페이지로 분리함으로써 피할 수 있다. 이 방법의 단점은 콜드 데이터를 가진 페이지들은 덜 자주 삭제(Erase)될 것이고, 이로 인해서 SSD 컨트롤러는 콜드 데이터와 핫 데이터를 가진 페이지들을 Wear Leveling을 위해서 주기적으로 스왑(swap) 해줘야 한다. 데이터의 변경 빈도는 응용 프로그램 레벨에서 결정되기 때문에, FTL은 하나의 페이지에 얼마나 핫 데이터와 콜드 데이터가 저장될지 예측할 수 있는 방법이 없다. SSD에서 성능을 향상시키기 위한 방법으로는 핫 데이터와 콜드 데이터를 최대한 다른 페이지로 분리하는 것이며, 이는 Garbage-collection이 좀 더 효율적으로 작동하도록 해준다12.
콜드 데이터와 핫 데이터 분리
빈번하게 변경되는 데이터를 핫 데이터라고 하며, 그렇지 않은 데이터를 콜드 데이터라고 한다. 만약 핫 데이터와 콜드 데이터가 동일 페이지에 저장된다면, 핫 데이터가 변경될 때마다 콜드 데이터는 핫 데이터와 함께 Read-Modify-Write 오퍼레이션에 같이 포함되어 복사되어야 한다. 또한 Wear-leveling을 위해서 콜드 데이터도 같이 계속 다른 페이지로 이동되어야 한다. 콜드 데이터와 핫 데이터는 최대한 분리해야 Garbage-collection을 효율적으로 처리될 수 있다.
핫 데이터 버퍼링
매우 빈번하게 변경되는 핫 데이터는 최대한 버퍼링되었다가 SSD에 덜 자주 업데이트되도록 하는 것이 좋다.
불필요한 데이터는 한번에 많이 삭제
데이터가 더 이상 필요치 않거나 삭제해야 할 때에는 최대한 모아서 한번(단일 오퍼레이션)에 삭제하는 것이 좋다. 이렇게 단일 오퍼레이션으로 삭제하는 것이 Garbage-collection 처리가 한번에 큰 영역을 처리하도록 해주며 그와 동시에 내부 프레그멘테이션을 최소화시켜 줄 것이다.
This articles are translated to Korean with original author’s(Emmanuel Goossaert) permission. Really appreciate his effort and sharing.
Original articles :
- Part 1: Introduction and Table of Contents
- Part 2: Architecture of an SSD and Benchmarking
- Part 3: Pages, Blocks, and the Flash Translation Layer
- Part 4: Advanced Functionalities and Internal Parallelism
- Part 5: Access Patterns and System Optimizations
- Part 6: A Summary – What every programmer should know about solid-state drives
References
-
Parameter-Aware I/O Management for Solid State Disks (SSDs), Kim et al., 2012 ↩ ↩2
-
Design Tradeoffs for SSD Performance, Agrawal et al., 2008 ↩ ↩2
-
Understanding Intrinsic Characteristics and System Implications of Flash Memory based Solid State Drives, Chen et al., 2009 ↩ ↩2 ↩3 ↩4
-
A Reconfigurable FTL (Flash Translation Layer) Architecture for NAND Flash-Based Applications, Park et al., 2008 ↩ ↩2 ↩3 ↩4
-
A Survey of Flash Translation Layer, Chung et al., 2009 ↩ ↩2 ↩3
-
http://en.wikipedia.org/wiki/List_of_solid-state_drive_manufacturers ↩
-
http://en.wikipedia.org/wiki/List_of_flash_memory_controller_manufacturers ↩
-
Essential roles of exploiting internal parallelism of flash memory based solid state drives in high-speed data processing, Chen et al, 2011 ↩
-
SFS: Random Write Considered Harmful in Solid State Drives, Min et al., 2012 ↩